The Final Round
This post is the natural sequel to my Wordle OpenEnv RL training run. That one was my first RL run where the reward curve actually went up and I could explain why, but it was still a warm up. The real hackathon task was to build an original OpenEnv environment, make it pass the required interface, and then show that a model can actually learn inside it.
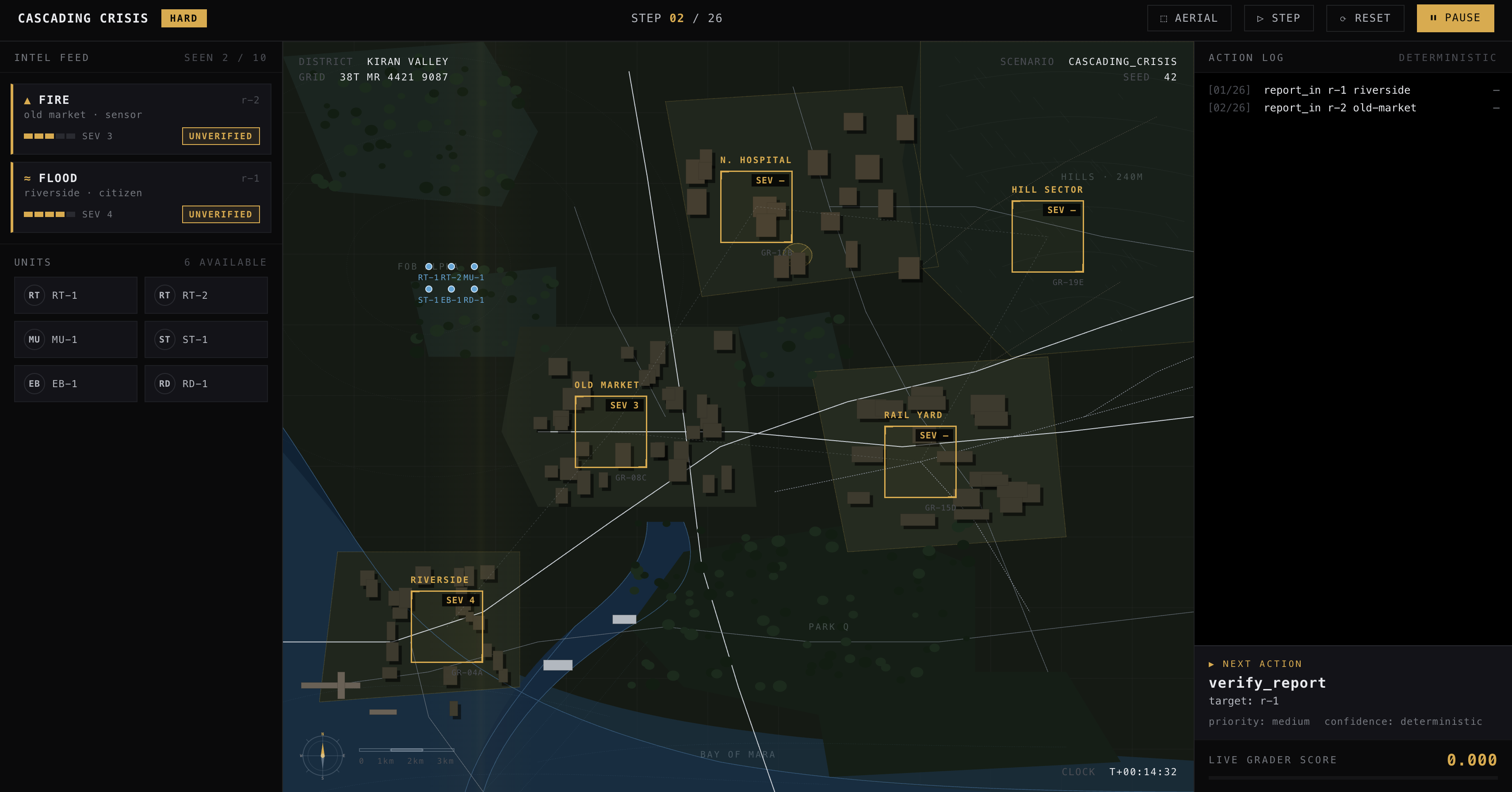
So for the final round of the Meta PyTorch OpenEnv Hackathon in Bangalore, I built CrisisOps. The idea was simple in my head, but not simple to build: what if an LLM had to act like an emergency operations commander during a city wide disaster? Not answer one question. Not classify one sample. Actually track a situation over many steps, deal with noisy reports, verify before acting, allocate limited resources, and publish a final situation report.
How I Got Here
Round 1 of the hackathon ran from March 25 to April 10, 2026. There was a lot of time, and I used it to get a feel for how OpenEnv actually works. I built json_cleaning_env as a warm-up trial: a simple JSON cleaning environment where the agent had to fix malformed JSON against a target schema. It was never meant to be my official submission. I treated it as a sketch to understand the interface, the grader loop, and what makes an environment feel "real" to an agent.
The actual submission I built later was DryLabSim, a dry-lab style environment where an agent plans and runs computational biology experiments under partial observability, noisy outputs, budget constraints, and scientific validity rules. That one was the real deal: deterministic grading, structured actions, hidden biological ground truth, and a live demo UI.
Both taught me how OpenEnv wants an environment to behave, but by the time the finale came around I wanted something heavier.
I wanted an environment where the model could not survive by just formatting output correctly. It had to carry state, make decisions in order, and handle the cost of doing things too early or too late. That is why CrisisOps became a disaster response environment.
What CrisisOps Actually Is
The agent sees a live crisis room view. There are zones with incidents, severity, deadlines, blocked access, and population at risk. There are reports from citizens, sensors, field teams, officials, and media. There are limited resources like rescue teams, medical units, evac buses, supply trucks, and recon drones. There is also an incident log that changes as the episode continues.
Then the model has to choose one action at a time. It can verify a report, flag a false alarm, allocate a unit, request recon, reroute a unit, issue an evacuation, open a shelter, dispatch supplies, publish a sitrep, or do nothing.
That action space is what made the project feel real to me. A bad action is not just "wrong." It has a reason it is wrong. Maybe the report was unverified. Maybe the unit type did not match the incident. Maybe the zone was blocked. Maybe the deadline passed while the model was still wandering around. That is the kind of failure mode I wanted.
The Four Difficulty Tiers
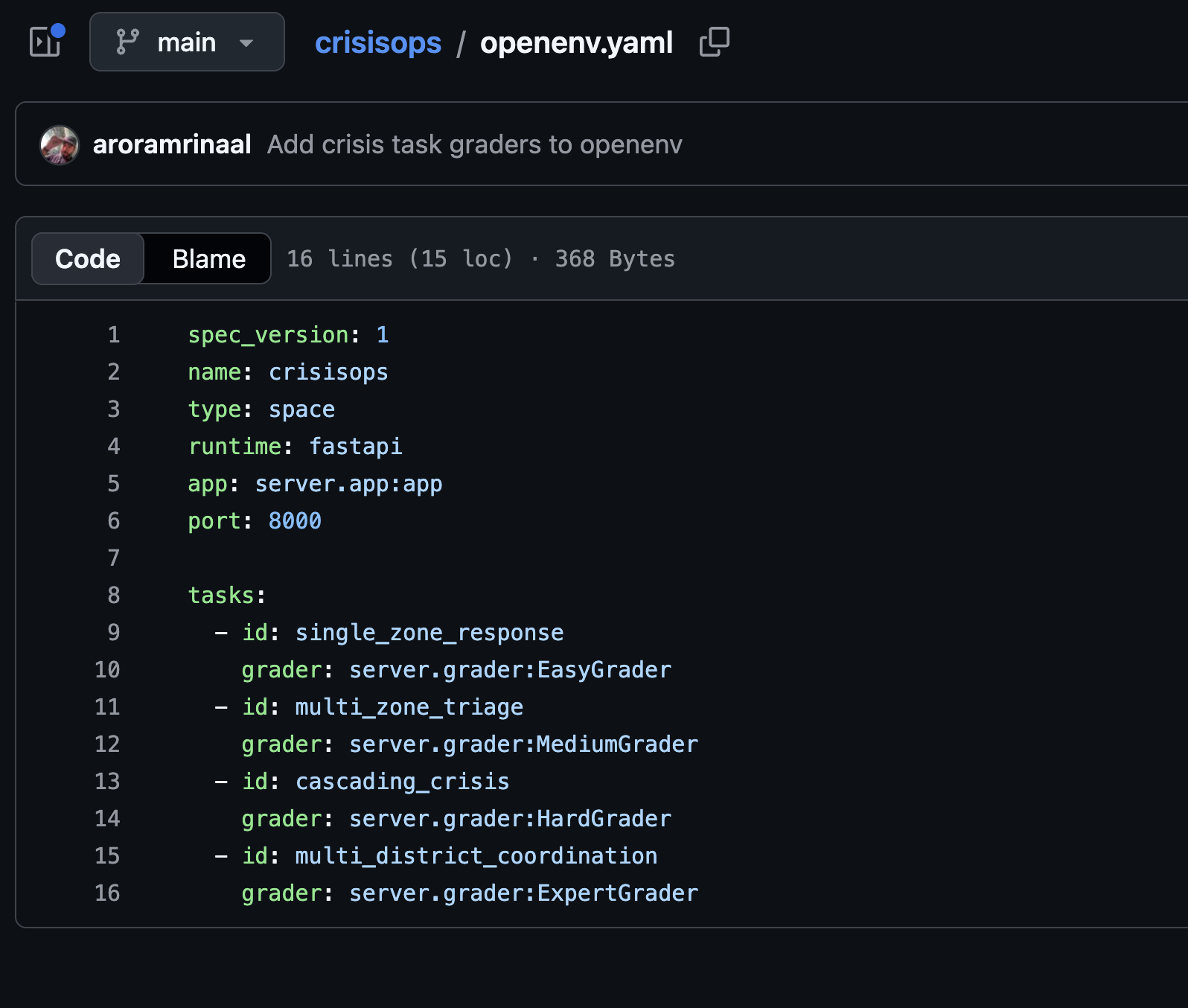
CrisisOps has four tasks. The easy tier is mostly about doing the basic crisis loop correctly: verify, allocate, and publish a sitrep. The medium tier adds multiple zones and false alarms. The hard tier starts forcing replanning because new events appear mid episode. The expert tier pushes into multi district coordination, mutual aid, and comms degradation.
| Tier |
Task ID |
What It Tests |
| Easy |
single_zone_response |
Verify, allocate, then publish a sitrep |
| Medium |
multi_zone_triage |
Handle multiple zones and false alarms |
| Hard |
cascading_crisis |
Replan when new events appear mid episode |
| Expert |
multi_district_coordination |
Multi district coordination, mutual aid, and comms degradation |
The hard tier is the one that felt closest to the idea in my head. Reports keep coming in, some things are uncertain, and the model has to adjust instead of just following a fixed script. The demo UI was mostly built so judges could see the shape of the problem quickly, but the actual environment is not the UI. The real thing is the OpenEnv server behind it.
The Interface Had To Be Real
One important part of this project was making the environment behave like a proper OpenEnv submission. The repo has the standard task manifest, graders, server, client, inference script, tests, and the HTTP control surface.
At one point this mattered a lot because the hackathon contract expected session backed HTTP routes: POST /reset, POST /step, and GET /state. That sounds boring, but it is exactly the kind of boring that matters. If the environment contract is wrong, the model training story does not matter. So before treating this as an RL project, I had to make sure it was a real environment.
Then I Tried To Train A Small Model On It
For training, I used Qwen/Qwen2.5-Coder-3B-Instruct through the Unsloth 4 bit model path, with LoRA adapters and TRL's GRPOTrainer. The final training runs happened on Modal's cloud GPU infra, using an NVIDIA H200.
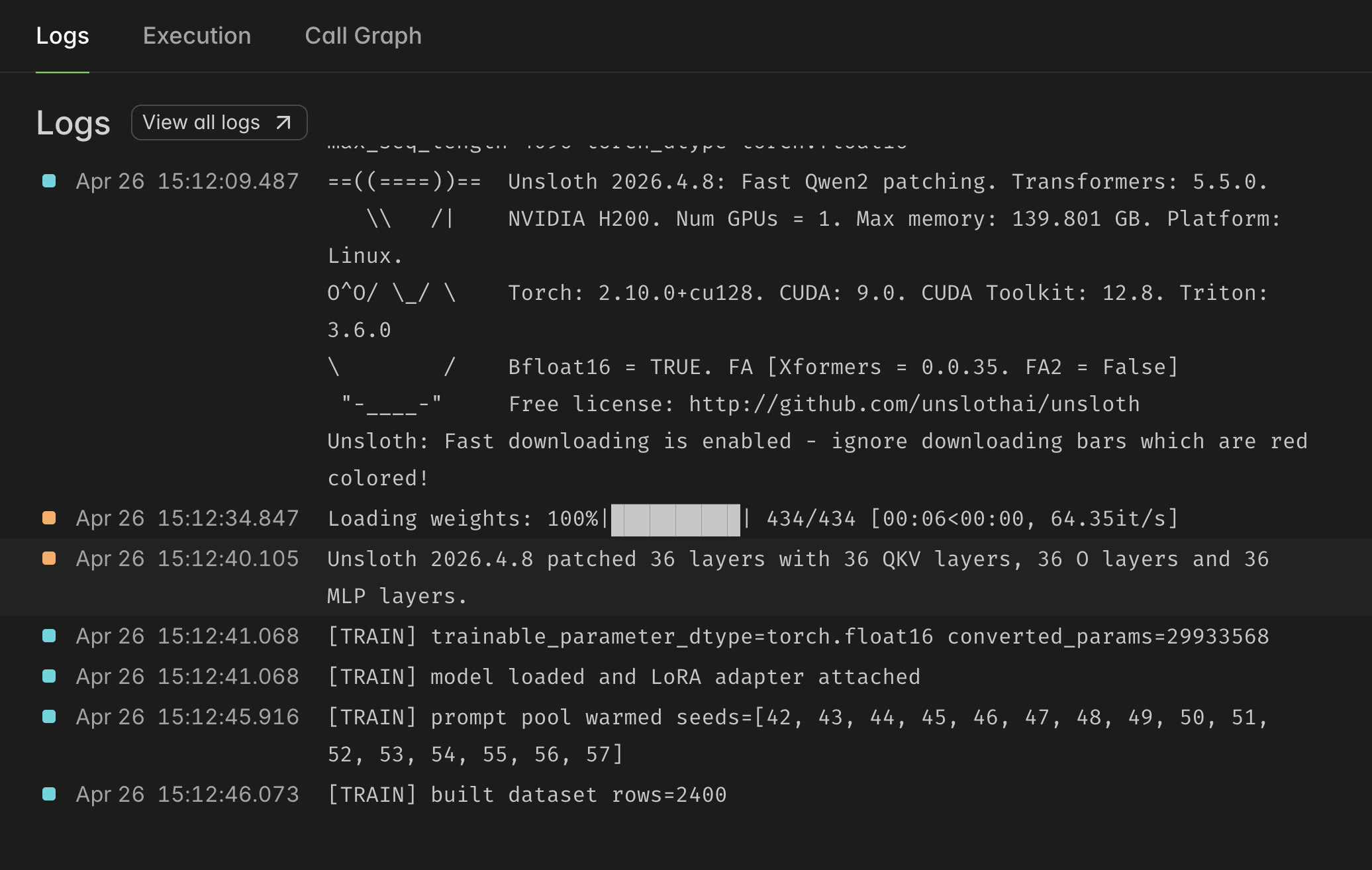
The training setup was not fancy in the storytelling sense. It was mostly plumbing: render the current CrisisOps observation into a compact prompt, ask the model for exactly one JSON action, parse and sanitize that action, send it to the live environment, read the reward back, and let GRPO compare the generated actions and update the model. The scripts are here: training-scripts.
The Runs
I ran three small GRPO runs: easy-task-grpo-run-1, medium-task-grpo-run-1, and medium-task-grpo-run-2. I kept them small because this was the hackathon finale and I was still trying to prove that the loop worked before pretending the system was solved.

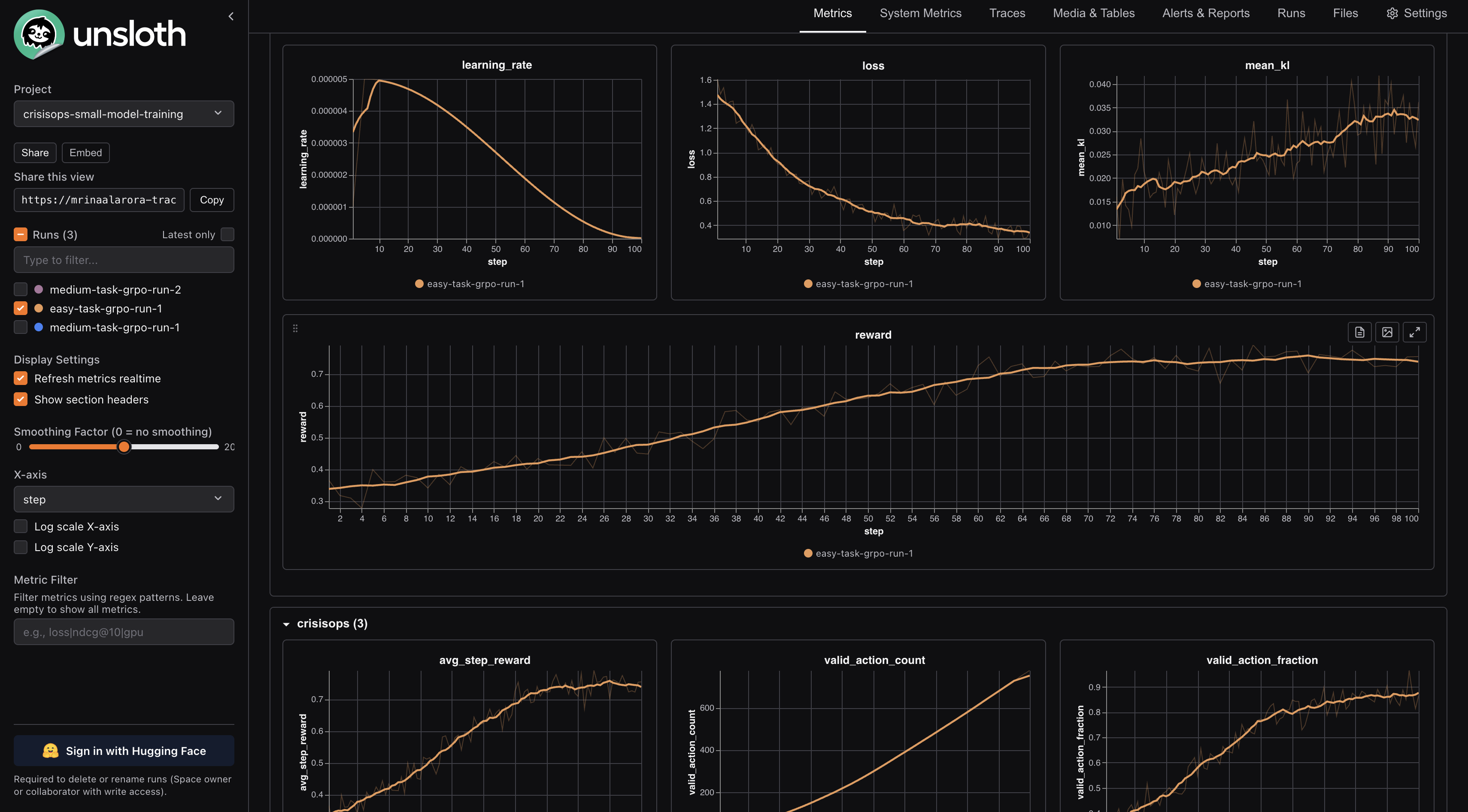
The easy run went from around 0.37 reward to around 0.75, which was the cleanest looking result. That made sense because the easy task is closest to the basic crisis loop: verify the report, allocate the right unit, and publish a sitrep.
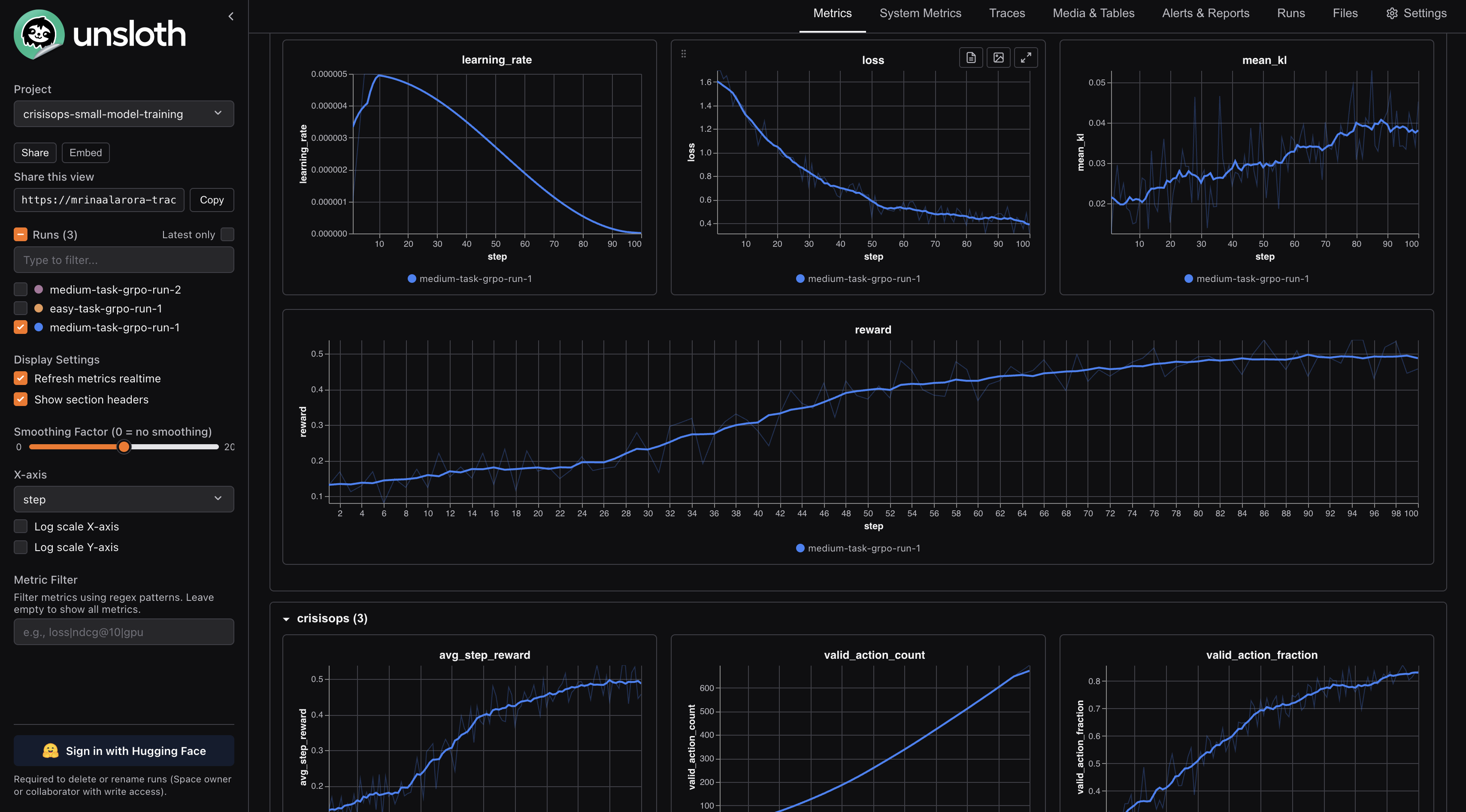
The first medium run went from around 0.13 to around 0.46. That jump mattered because medium is no longer just one obvious incident. The model has to deal with multiple zones and the possibility that some reports are false alarms.
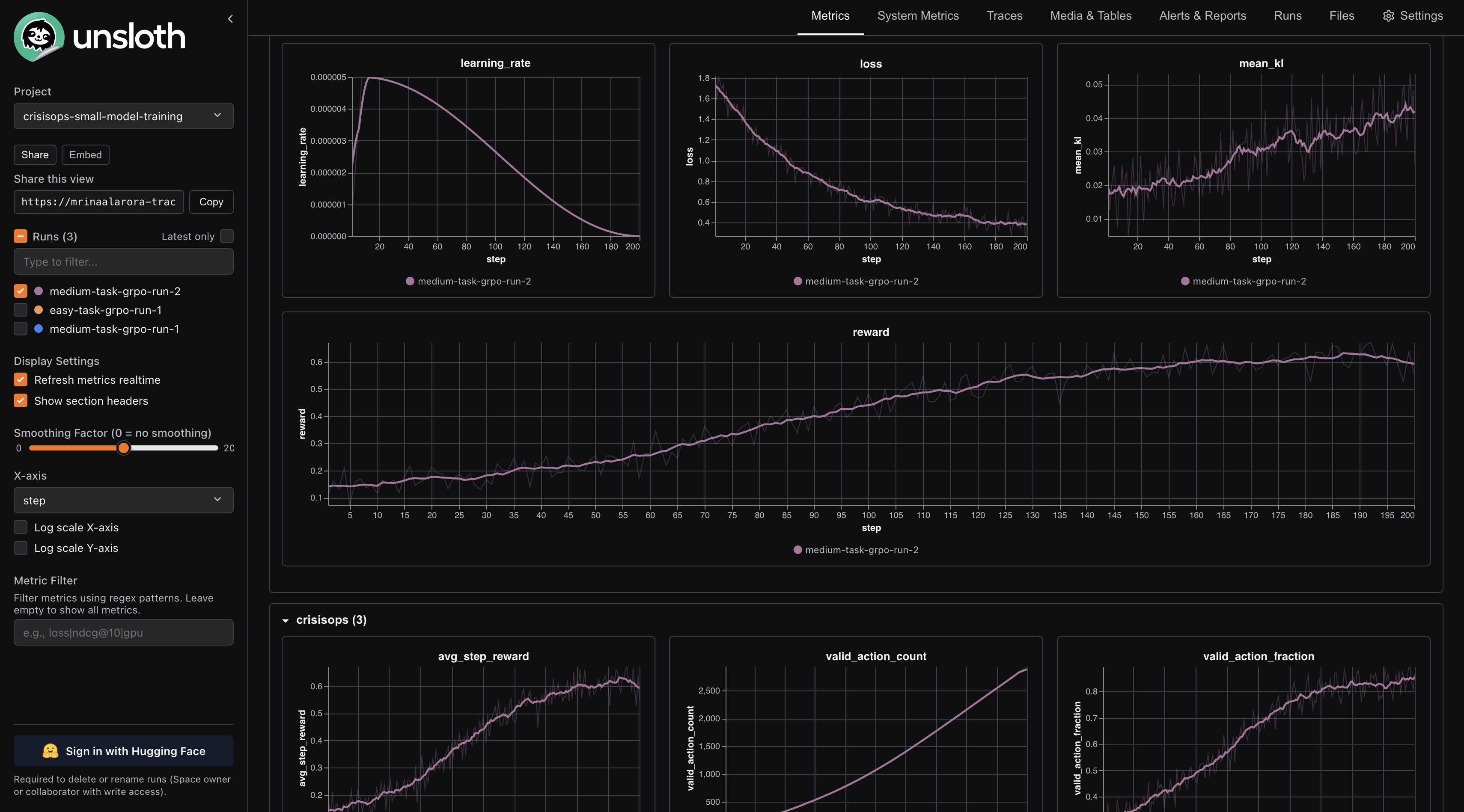
The second medium run was longer and went from around 0.11 to around 0.55. It was not perfectly smooth, but it was the kind of curve I wanted to see: reward moving up while loss moved down, without the run looking mechanically broken.
You can see the full dashboard here: Trackio dashboard. I like keeping the dashboard linked because otherwise it is too easy to make the result sound cleaner than it was.
What I Think The Model Learned
I do not want to oversell it. This was not a magic moment where a small model suddenly became a perfect emergency commander. The hard and expert tiers are still genuinely hard. But the curves did move in the right direction, and the movement made sense.
The model became better at producing valid action JSON, better at taking actions that the environment accepted, and better at getting reward for the simple but important behaviors: verify reports, avoid obvious invalid actions, and allocate resources more sensibly. That is enough for me to call this a real RL training result, especially because the environment was not a toy single turn reward parser. The model was interacting with a live stateful system.
The biggest difference from my earlier RL experiments is that here I built the task too. So when the reward moved, I understood both sides of the loop: the model side and the environment side.
The Part That Felt Most Different
In the Wordle post, I wrote that OpenEnv made RL environments feel like microservices. CrisisOps made that idea much more concrete. The environment was a server. The model was a client. The trainer did not need to know every internal rule. It only needed to reset, step, observe, and learn from reward.
That separation felt clean, and it also made the project feel closer to the kind of RL I actually care about. Not just "can the model solve a benchmark," but "can the model act inside a small world with rules, memory, uncertainty, and consequences." That is why this project mattered to me.
What I Would Improve Next
If I keep working on CrisisOps, I would improve three things first. I would train longer and evaluate more carefully across all four tiers. I would make the reward decomposition more visible, so I can see exactly which behavior is improving. Valid JSON is useful, but it should not hide whether the model is actually planning better.
I would also make baseline comparisons stricter. A model should not get called "good" just because it did not crash. It should resolve the crisis better than before. That is the lesson I keep relearning in RL. The graph is not the whole truth. You have to know what behavior the graph is actually rewarding.
Where This Leaves Me
This whole hackathon arc started with me trying to understand what an RL environment even is. Then I trained a model on Wordle and saw my first reward curve go up. Then I built an original OpenEnv environment for the final round and trained a small model inside it using TRL, Unsloth, and Modal.
That sequence matters to me because it did not feel like random projects. Each one exposed the next missing piece. First I needed to understand reward design. Then I needed to understand environment hosting. Then I needed to build the environment myself.
CrisisOps is not perfect, but it is the first time I felt like I had built the whole loop: task, server, grader, demo, training script, logs, curves, and writeup. That feels like a good place to end this hackathon chapter.
Links
CrisisOps
Earlier Hackathon Submissions
Previous RL Posts
The Final Round
This post is the natural sequel to my Wordle OpenEnv RL training run. That one was my first RL run where the reward curve actually went up and I could explain why, but it was still a warm up. The real hackathon task was to build an original OpenEnv environment, make it pass the required interface, and then show that a model can actually learn inside it.
So for the final round of the Meta PyTorch OpenEnv Hackathon in Bangalore, I built CrisisOps. The idea was simple in my head, but not simple to build: what if an LLM had to act like an emergency operations commander during a city wide disaster? Not answer one question. Not classify one sample. Actually track a situation over many steps, deal with noisy reports, verify before acting, allocate limited resources, and publish a final situation report.
How I Got Here
Round 1 of the hackathon ran from March 25 to April 10, 2026. There was a lot of time, and I used it to get a feel for how OpenEnv actually works. I built json_cleaning_env as a warm-up trial: a simple JSON cleaning environment where the agent had to fix malformed JSON against a target schema. It was never meant to be my official submission. I treated it as a sketch to understand the interface, the grader loop, and what makes an environment feel "real" to an agent.
The actual submission I built later was DryLabSim, a dry-lab style environment where an agent plans and runs computational biology experiments under partial observability, noisy outputs, budget constraints, and scientific validity rules. That one was the real deal: deterministic grading, structured actions, hidden biological ground truth, and a live demo UI.
Both taught me how OpenEnv wants an environment to behave, but by the time the finale came around I wanted something heavier.
I wanted an environment where the model could not survive by just formatting output correctly. It had to carry state, make decisions in order, and handle the cost of doing things too early or too late. That is why CrisisOps became a disaster response environment.
What CrisisOps Actually Is
The agent sees a live crisis room view. There are zones with incidents, severity, deadlines, blocked access, and population at risk. There are reports from citizens, sensors, field teams, officials, and media. There are limited resources like rescue teams, medical units, evac buses, supply trucks, and recon drones. There is also an incident log that changes as the episode continues.
Then the model has to choose one action at a time. It can verify a report, flag a false alarm, allocate a unit, request recon, reroute a unit, issue an evacuation, open a shelter, dispatch supplies, publish a sitrep, or do nothing.
That action space is what made the project feel real to me. A bad action is not just "wrong." It has a reason it is wrong. Maybe the report was unverified. Maybe the unit type did not match the incident. Maybe the zone was blocked. Maybe the deadline passed while the model was still wandering around. That is the kind of failure mode I wanted.
The Four Difficulty Tiers
CrisisOps has four tasks. The easy tier is mostly about doing the basic crisis loop correctly: verify, allocate, and publish a sitrep. The medium tier adds multiple zones and false alarms. The hard tier starts forcing replanning because new events appear mid episode. The expert tier pushes into multi district coordination, mutual aid, and comms degradation.
single_zone_responsemulti_zone_triagecascading_crisismulti_district_coordinationThe hard tier is the one that felt closest to the idea in my head. Reports keep coming in, some things are uncertain, and the model has to adjust instead of just following a fixed script. The demo UI was mostly built so judges could see the shape of the problem quickly, but the actual environment is not the UI. The real thing is the OpenEnv server behind it.
The Interface Had To Be Real
One important part of this project was making the environment behave like a proper OpenEnv submission. The repo has the standard task manifest, graders, server, client, inference script, tests, and the HTTP control surface.
At one point this mattered a lot because the hackathon contract expected session backed HTTP routes:
POST /reset,POST /step, andGET /state. That sounds boring, but it is exactly the kind of boring that matters. If the environment contract is wrong, the model training story does not matter. So before treating this as an RL project, I had to make sure it was a real environment.Then I Tried To Train A Small Model On It
For training, I used
Qwen/Qwen2.5-Coder-3B-Instructthrough the Unsloth 4 bit model path, with LoRA adapters and TRL'sGRPOTrainer. The final training runs happened on Modal's cloud GPU infra, using an NVIDIA H200.The training setup was not fancy in the storytelling sense. It was mostly plumbing: render the current CrisisOps observation into a compact prompt, ask the model for exactly one JSON action, parse and sanitize that action, send it to the live environment, read the reward back, and let GRPO compare the generated actions and update the model. The scripts are here: training-scripts.
The Runs
I ran three small GRPO runs:
easy-task-grpo-run-1,medium-task-grpo-run-1, andmedium-task-grpo-run-2. I kept them small because this was the hackathon finale and I was still trying to prove that the loop worked before pretending the system was solved.The easy run went from around
0.37reward to around0.75, which was the cleanest looking result. That made sense because the easy task is closest to the basic crisis loop: verify the report, allocate the right unit, and publish a sitrep.The first medium run went from around
0.13to around0.46. That jump mattered because medium is no longer just one obvious incident. The model has to deal with multiple zones and the possibility that some reports are false alarms.The second medium run was longer and went from around
0.11to around0.55. It was not perfectly smooth, but it was the kind of curve I wanted to see: reward moving up while loss moved down, without the run looking mechanically broken.You can see the full dashboard here: Trackio dashboard. I like keeping the dashboard linked because otherwise it is too easy to make the result sound cleaner than it was.
What I Think The Model Learned
I do not want to oversell it. This was not a magic moment where a small model suddenly became a perfect emergency commander. The hard and expert tiers are still genuinely hard. But the curves did move in the right direction, and the movement made sense.
The model became better at producing valid action JSON, better at taking actions that the environment accepted, and better at getting reward for the simple but important behaviors: verify reports, avoid obvious invalid actions, and allocate resources more sensibly. That is enough for me to call this a real RL training result, especially because the environment was not a toy single turn reward parser. The model was interacting with a live stateful system.
The biggest difference from my earlier RL experiments is that here I built the task too. So when the reward moved, I understood both sides of the loop: the model side and the environment side.
The Part That Felt Most Different
In the Wordle post, I wrote that OpenEnv made RL environments feel like microservices. CrisisOps made that idea much more concrete. The environment was a server. The model was a client. The trainer did not need to know every internal rule. It only needed to reset, step, observe, and learn from reward.
That separation felt clean, and it also made the project feel closer to the kind of RL I actually care about. Not just "can the model solve a benchmark," but "can the model act inside a small world with rules, memory, uncertainty, and consequences." That is why this project mattered to me.
What I Would Improve Next
If I keep working on CrisisOps, I would improve three things first. I would train longer and evaluate more carefully across all four tiers. I would make the reward decomposition more visible, so I can see exactly which behavior is improving. Valid JSON is useful, but it should not hide whether the model is actually planning better.
I would also make baseline comparisons stricter. A model should not get called "good" just because it did not crash. It should resolve the crisis better than before. That is the lesson I keep relearning in RL. The graph is not the whole truth. You have to know what behavior the graph is actually rewarding.
Where This Leaves Me
This whole hackathon arc started with me trying to understand what an RL environment even is. Then I trained a model on Wordle and saw my first reward curve go up. Then I built an original OpenEnv environment for the final round and trained a small model inside it using TRL, Unsloth, and Modal.
That sequence matters to me because it did not feel like random projects. Each one exposed the next missing piece. First I needed to understand reward design. Then I needed to understand environment hosting. Then I needed to build the environment myself.
CrisisOps is not perfect, but it is the first time I felt like I had built the whole loop: task, server, grader, demo, training script, logs, curves, and writeup. That feels like a good place to end this hackathon chapter.
Links
CrisisOps
Earlier Hackathon Submissions
Previous RL Posts