
Why I Tried This
In April I decided to participate in OpenAI Model Craft: Parameter Golf. The challenge was to train the best language model that fits inside a 16 MB artifact and finishes training in under 10 minutes on 8xH100 SXM GPUs. The score is bits per byte on FineWeb validation, so lower is better.
What made it interesting to me was that there was no hard parameter count limit. The real limit was whether the final artifact fit, whether training finished in time, and whether the model actually compressed text better. It was not just "make the model bigger." It was more like: can you make something small, compressed, slightly weird, and still useful?
I started late. The challenge ran from March 18 to April 30, 2026, but I only started properly around April 17. So I was not entering with a polished research plan. I was entering with curiosity, a fork of the repo, cloud GPU credits, and a lot of questions.
The First Thing I Had To Understand
The first thing I had to understand was BPB, or bits per byte. I understood it as a tokenizer agnostic compression score. That mattered because I could try different tokenizers and vocab sizes, but the final evaluation still came back to the same thing: how well the model compressed the validation bytes.
The next thing was artifact size. At first 16 MB sounds impossibly tiny, but the baseline exports the model through int8 plus zlib compression, so raw model size has more room than it first looks like. Still, size became the thing I had to keep checking again and again. A run could have a better val_bpb, but if the compressed artifact crossed 16,000,000 bytes, it was not useful for the actual challenge.
That became the first real lesson for me: in Parameter Golf, a result is not a result until the score and the artifact size both survive.
Starting On RunPod
I first tried the official RunPod path because the challenge was built around RunPod and had a template for it.
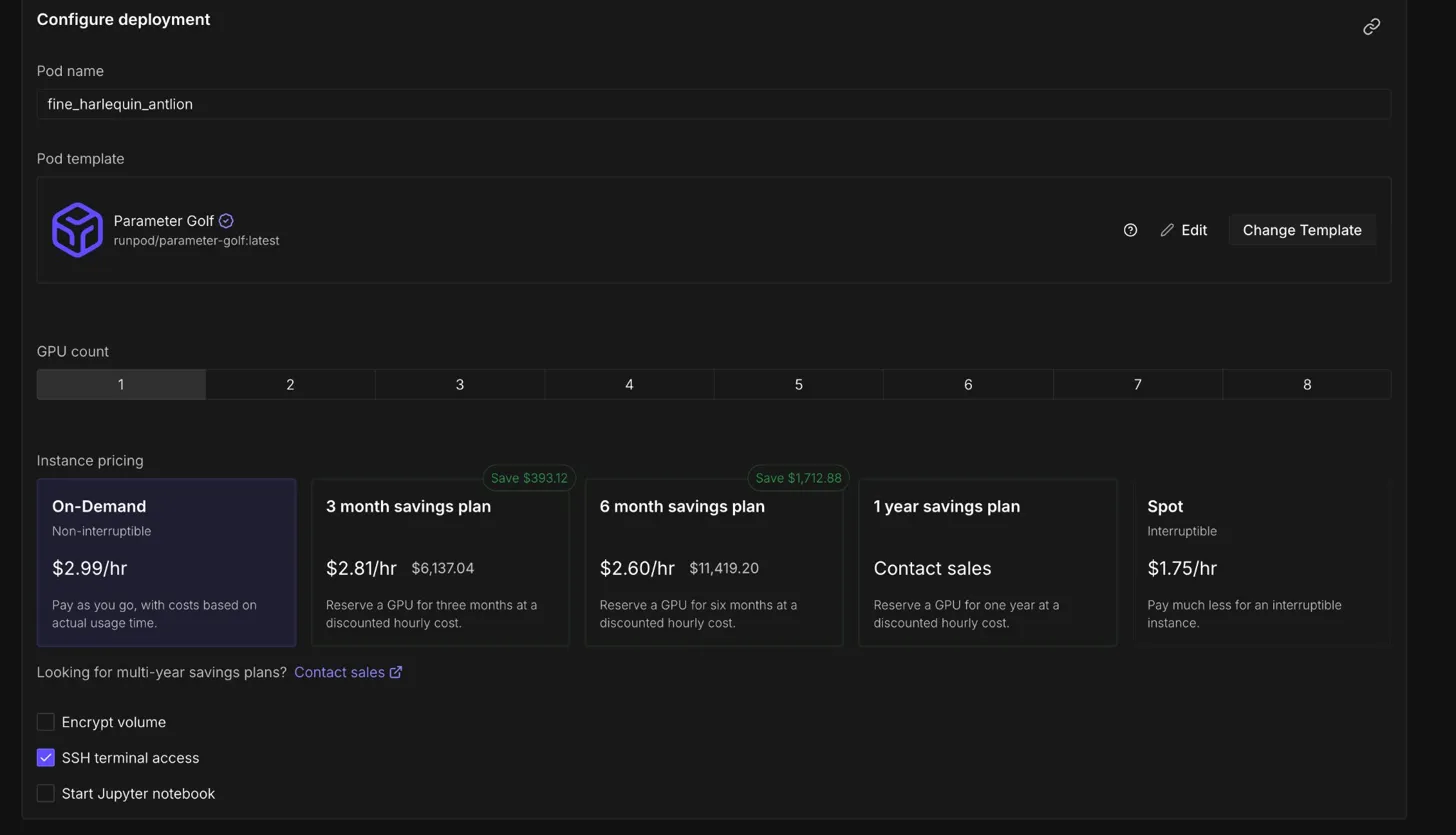
The setup was fairly direct. Create a pod, pick the Parameter Golf template, attach storage, SSH in, clone the repo, download the data, and run the training script. I also learned very quickly that storage choices matter here because the pod can be temporary, while the experiments need to survive beyond one session.
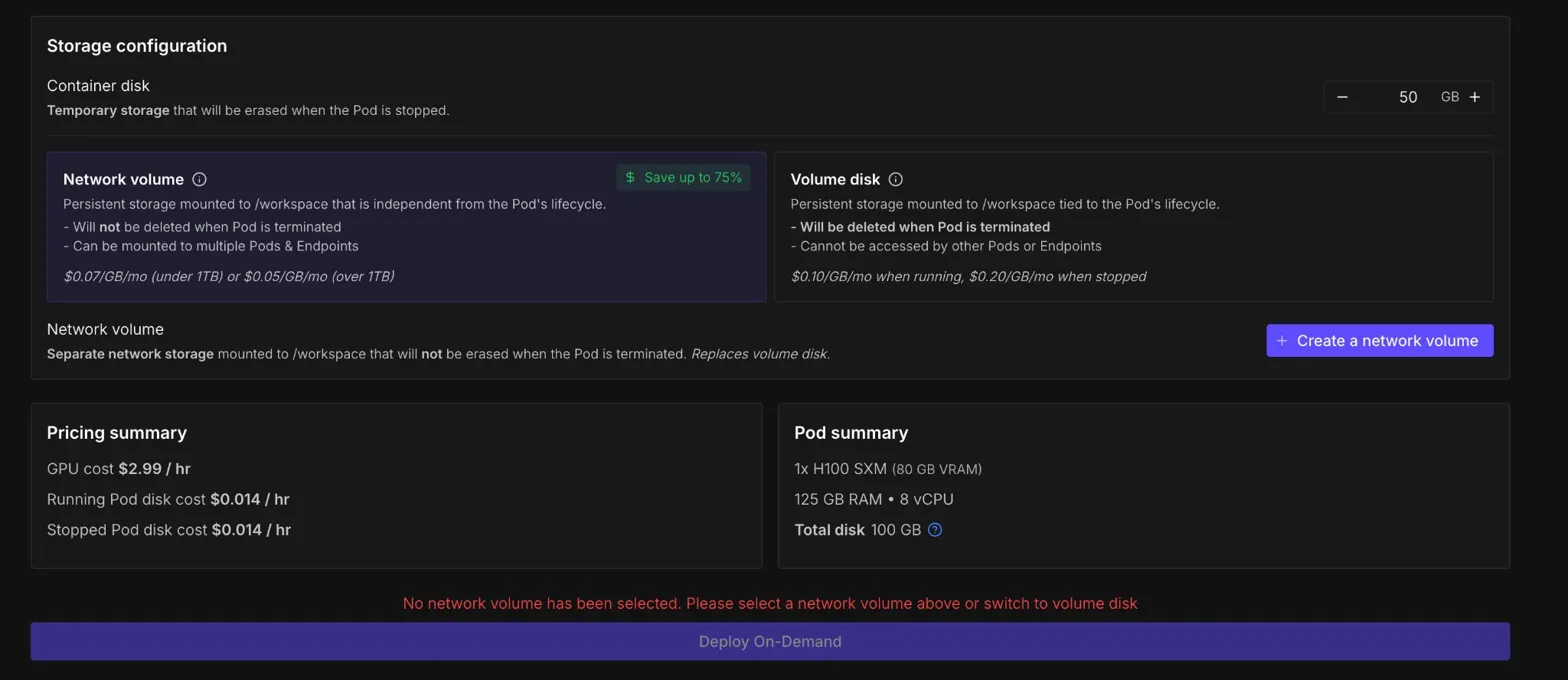
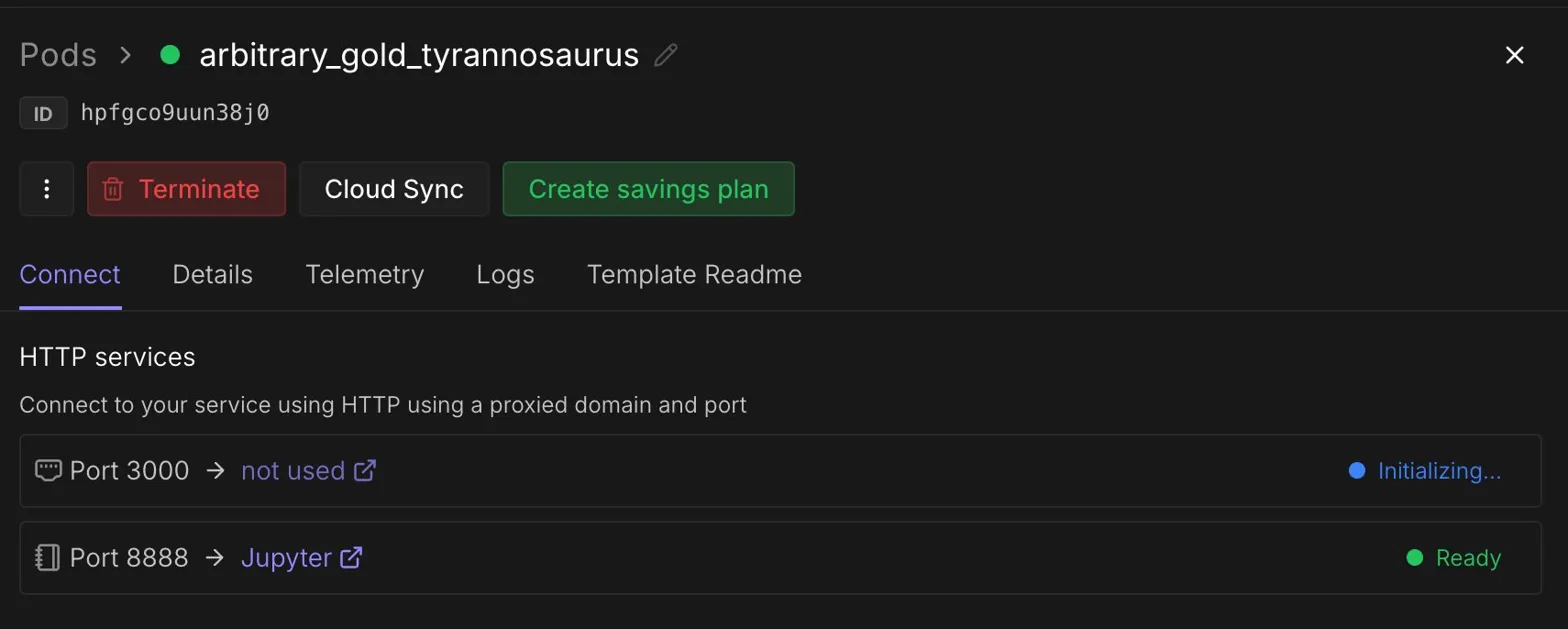
My first personal baseline was the unmodified OpenAI provided code on 1xH100, one training shard, and the 10 minute wallclock cap.
RUN_ID=baseline_sp1024
DATA_PATH=./data/datasets/fineweb10B_sp1024/
TOKENIZER_PATH=./data/tokenizers/fineweb_1024_bpe.model
VOCAB_SIZE=1024
torchrun --standalone --nproc_per_node=1 train_gpt.py
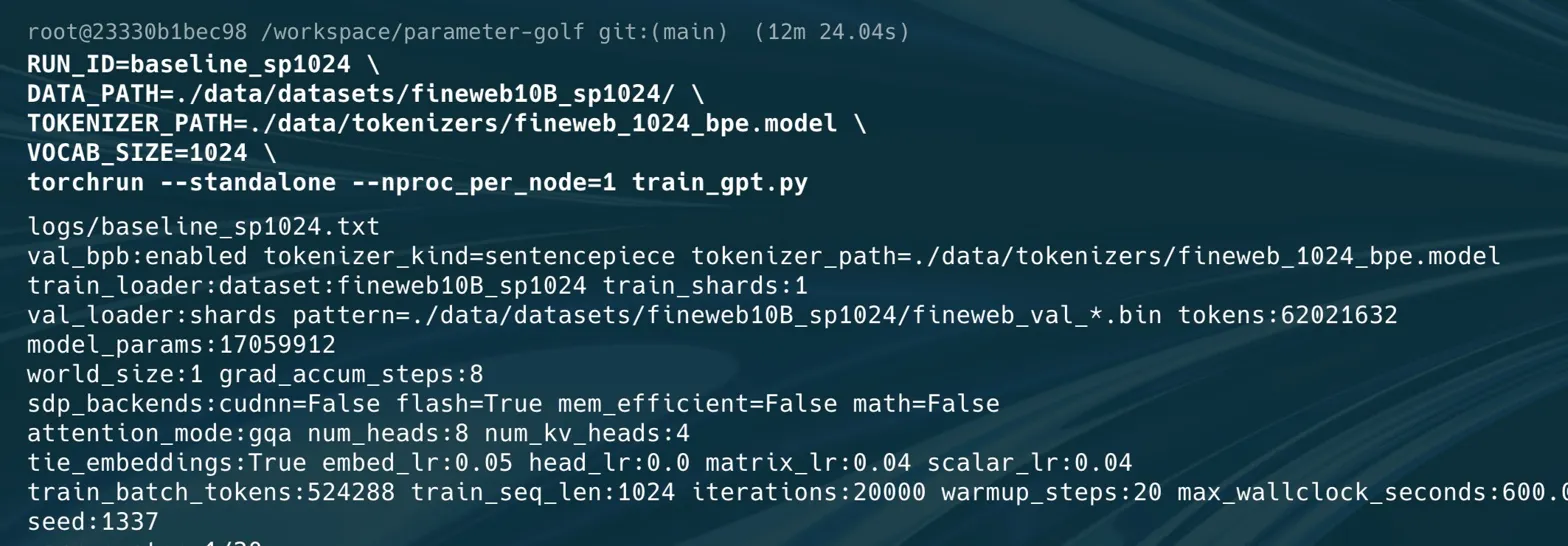
That run gave me a val_bpb of 1.36785005, a val_loss of 2.30955750, and 1161 steps before the wallclock cap. The raw submission was around 67.3 MB, but after int8 plus zlib compression it came down to around 13.1 MB, which was safely inside the 16 MB limit. Peak memory was only around 10.2 GiB, so at least on the baseline path, memory was not the scary part.
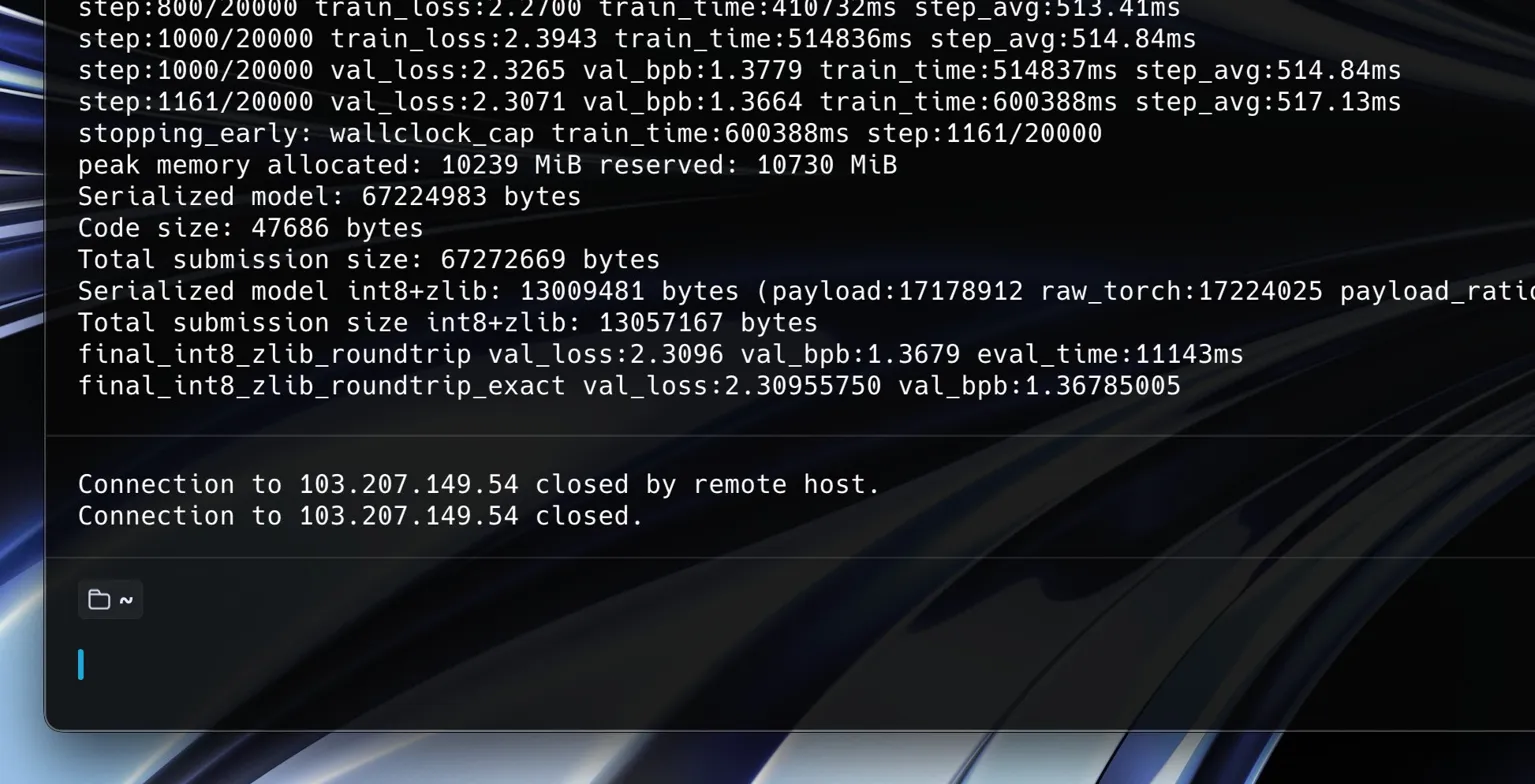
That number became my personal benchmark. If a change did not beat 1.36785 on roughly the same 1xH100 setup, I knew it was probably not worth thinking about as a serious direction. The official leaderboard was a very different world though. Around mid April, the top scores were already much lower, and they were using techniques I had not explored yet.
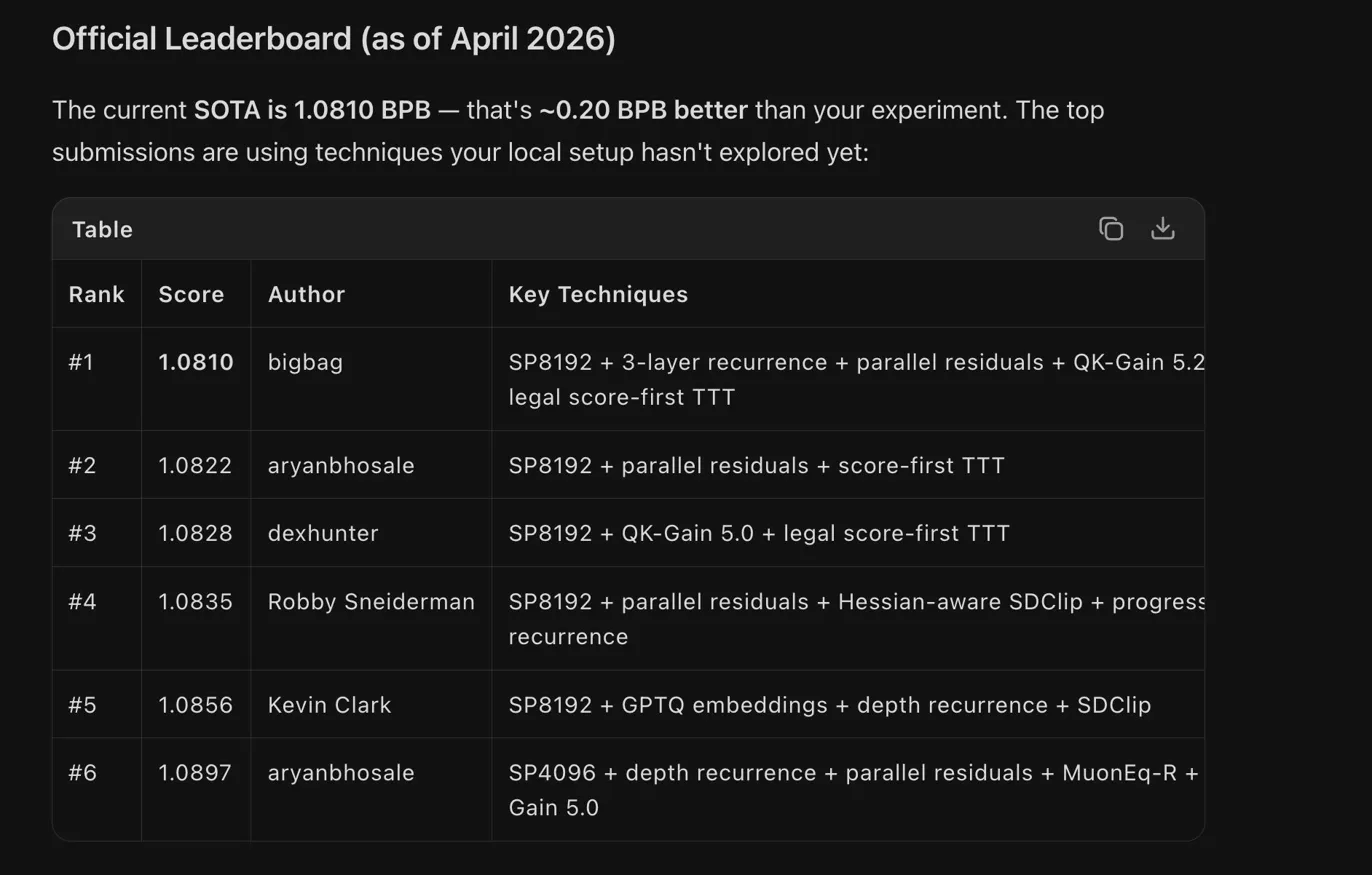
So I kept two comparisons separate in my head. My 1xH100 baseline was for learning and comparing my own ideas. The leaderboard was the real mountain.
Why I Moved To Modal
RunPod worked, but for my way of experimenting it felt risky. I was doing short runs, debugging runs, one minute sanity checks, and then 10 minute comparison runs. With RunPod, I had to stay aware of the pod being alive even when I was just reading logs or editing files. That is not ideal when most of the work is iteration.
Modal fit my workflow better because I already use it for my ML experiments, and it charges for active compute time. I could launch detached jobs, save logs and models into a volume, and avoid the feeling that idle infrastructure was quietly eating money.
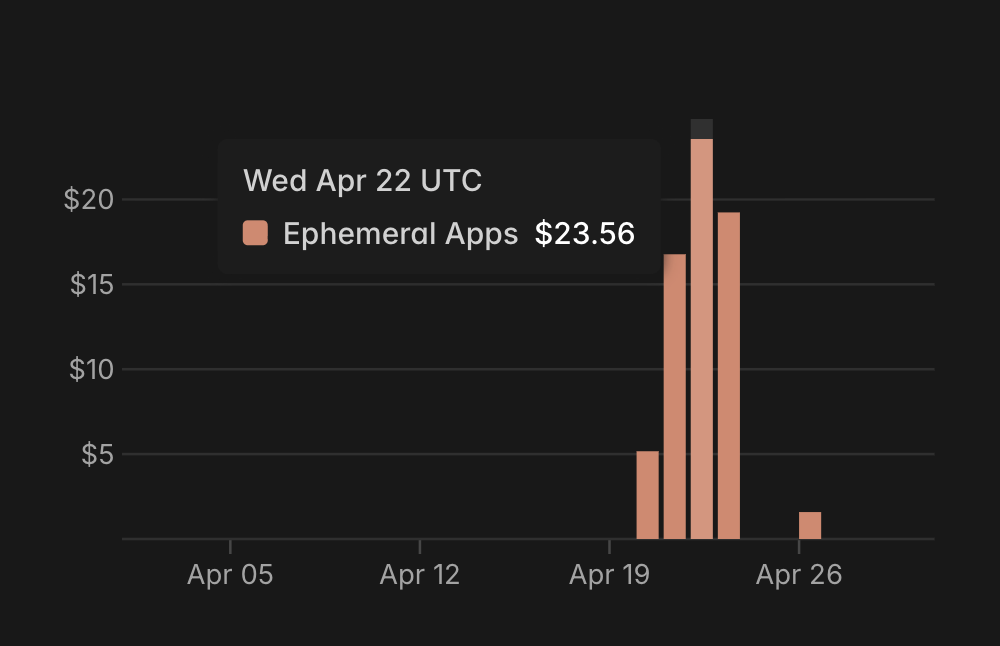
The cost view made this very concrete. Most of my Parameter Golf spend sat under ephemeral app runs, and the chart clearly showed the bursty nature of the work. This is exactly why Modal made sense for me here. I was not trying to keep a long running machine alive. I was trying to run a lot of short experiments without turning every pause into a cost problem.
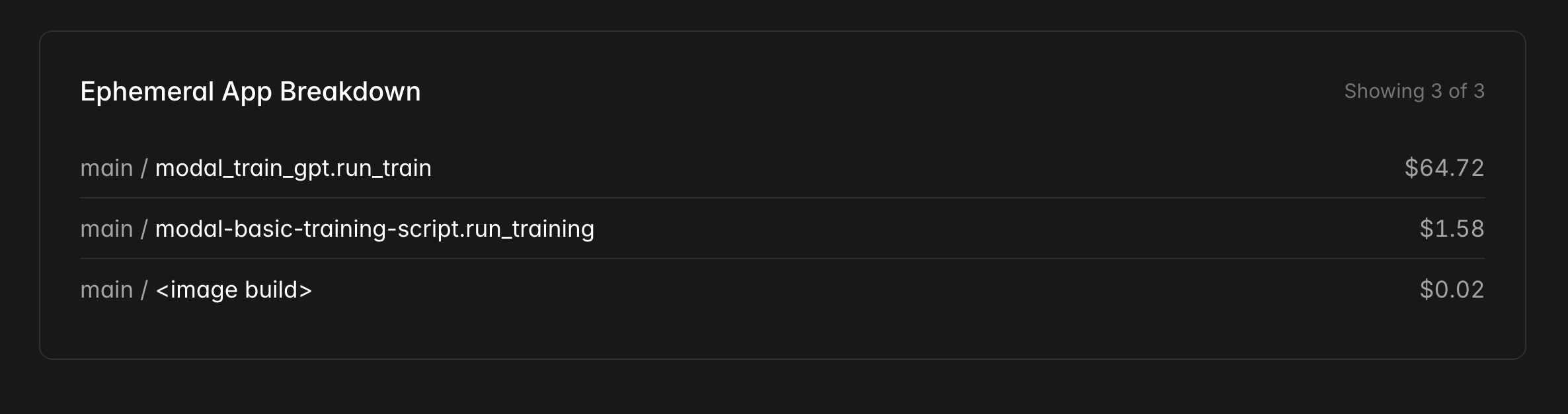
The final setup became my fork of OpenAI's Parameter Golf repo, on the mri/lab-setup branch, running through modal_train_gpt.py on 1xH100 SXM with one training shard and a 10 minute wallclock cap. I stored logs in /mnt/experiments/logs/, models in /mnt/experiments/models/, and kept the run history in EXPERIMENTS.md because without a tracker these experiments become impossible to reason about.
My Experiment Strategy
The workflow became simple: run tiny jobs to catch bugs, then run 10 minute 1xH100 jobs for real comparisons, and only think about 8xH100 if the idea already looked good and the artifact size was valid. I did not want to spend final submission level money on a broken idea.
The early wins came from boring changes. Longer sequence length helped. More layers sometimes helped, but crossed the size limit. sp4096 with sliding evaluation became the first direction that felt actually interesting.
| Experiment |
val_bpb |
Delta vs baseline |
Size |
Valid |
Baseline sp1024 |
1.36785 |
0.0000 |
13.1 MB |
yes |
sp4096 sliding eval |
1.28724 |
-0.0806 |
15.37 MB |
yes |
sp4096 QK gain 5.0 |
1.28397 |
-0.0839 |
15.51 MB |
yes |
sp8192 loop parallel |
1.28052 |
-0.0873 |
21.31 MB |
no |
← Swipe table to see more
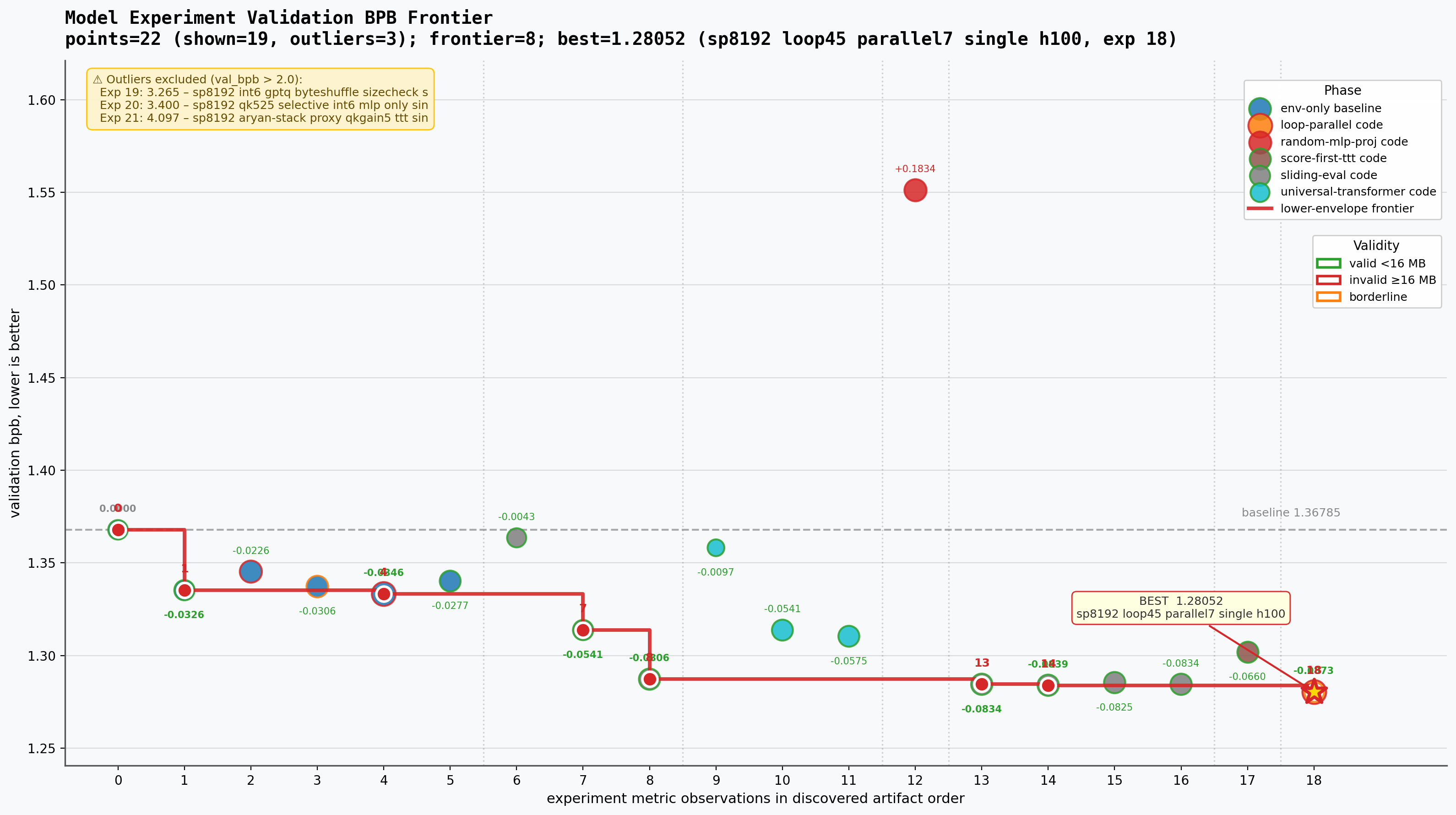
The BPB frontier plot makes the progression easier to see than the table alone. The red lower envelope is basically the path of ideas that actually moved my score down. A lot of runs existed around it, but only a few changed the frontier.
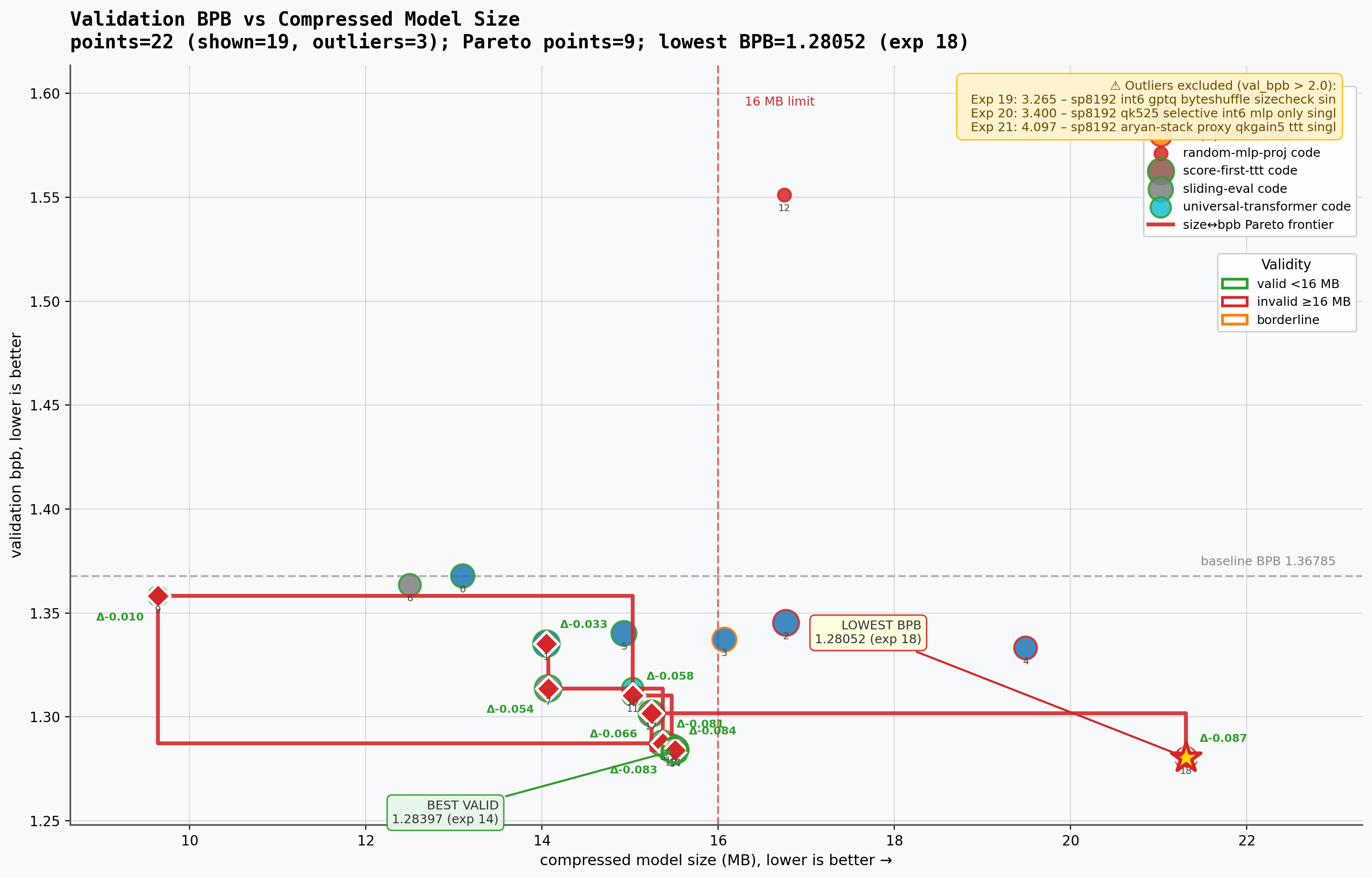
The size plot is the more painful one. It shows why the last row is such a Parameter Golf result. The sp8192 loop parallel run had the lowest BPB I saw, but it landed far beyond the 16 MB line. The best valid run was not the best scoring run, and that difference is basically the whole challenge.
The Ideas I Tried
The early phase was env only. I changed things through environment variables forwarded into the training script, mostly to understand which knobs mattered before touching code. After that I added the sliding evaluation path, where validation could use overlapping windows instead of only the stock evaluation route. That change helped the sp4096 setup a lot and became one of the clearer improvements in the whole run history.
Then I tried a Universal Transformer style idea with fewer physical blocks, more virtual depth, and depth conditioning. I liked the idea because it felt different and parameter efficient, but the aggressive shared block version did not beat the simpler sp4096 direction. A less aggressive half untied version was better, but still not enough to become the main path.
After that I tried a random MLP projection adapter idea, and that one failed badly. It got worse and the artifact was invalid. I also tried score first test time training. My understanding from this run was that TTT needs a strong enough base model to be useful. Enabling it too early did not help me. It made the score worse.
The final interesting direction was sp8192 with looped layers and parallel residual style changes. Those runs got closer on score, but the size problem became much harder because the embeddings were large. I also learned that compression and quantization can look promising before export, then collapse after the roundtrip validation. That is a brutal but useful kind of failure because it tells you exactly where the idea broke.
This is the part I liked most about the challenge. The failure modes were not vague. A run could have a good score but be too large. It could fit under the size limit but score worse. It could have clever quantization but collapse after export. It could add architecture complexity but then get fewer steps before the wallclock cap. Every idea had a cost.
A Modal Run That Felt Like The Real Setup
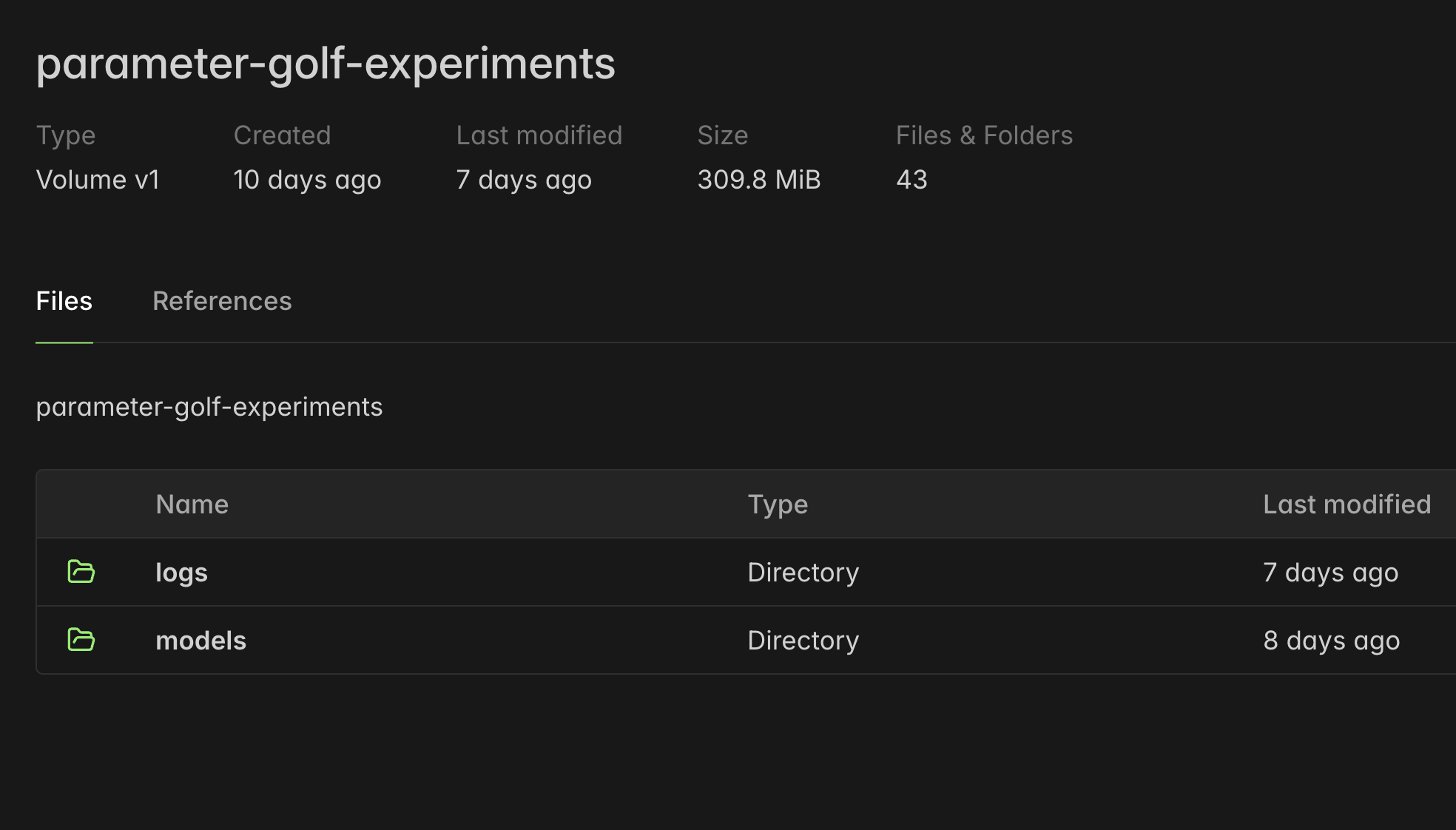
Once the Modal flow was working, the runs felt cleaner.
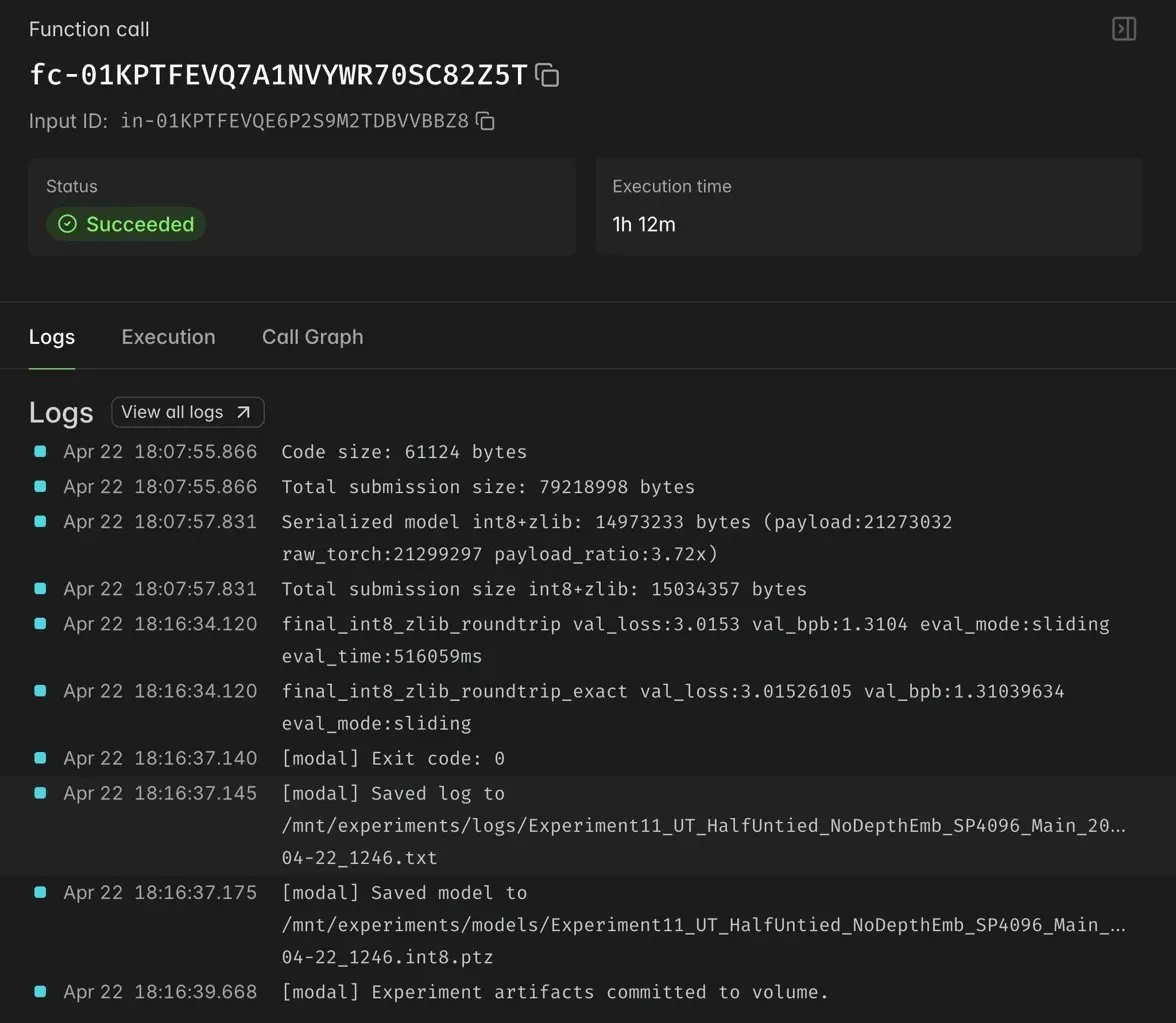
This screenshot is from one of the Universal Transformer follow up runs. It finished successfully, saved the log, saved the int8 model artifact, and committed everything to the Modal volume.
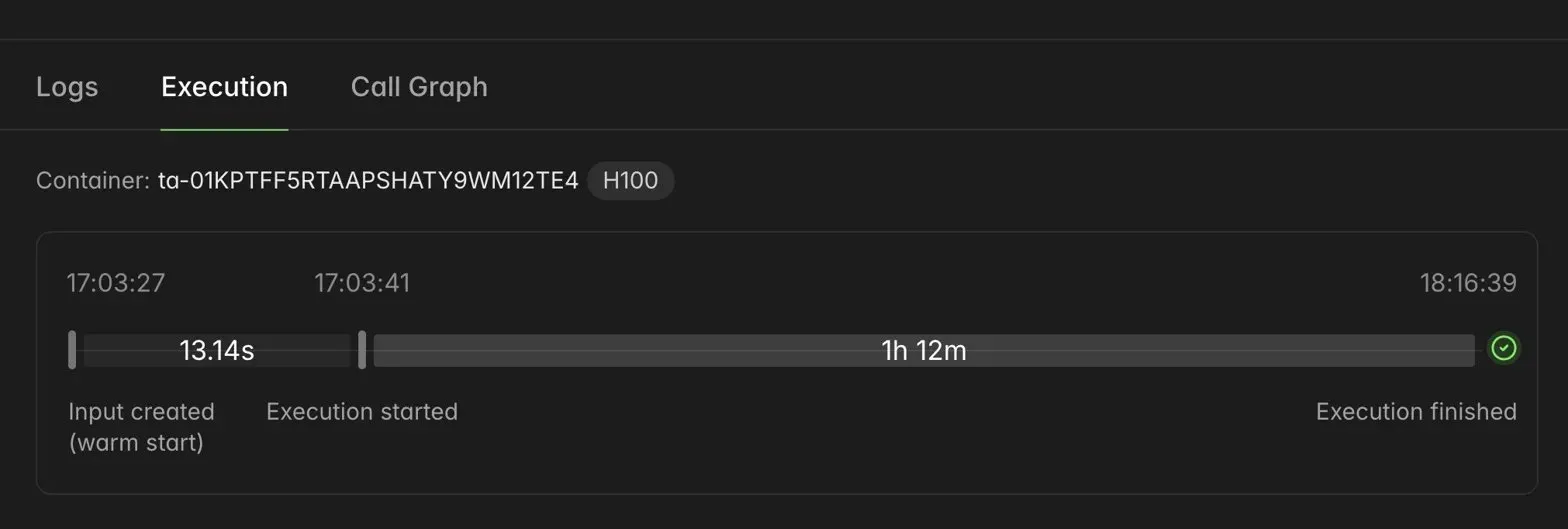
The run itself was not some leaderboard breakthrough, but the infrastructure finally felt like something I could trust. I could launch an experiment, walk away, and come back to logs and artifacts in the same place. That matters a lot when the whole game is iteration.
The Auto Research Agent Thing
One reason this challenge stayed in my head was Modal's own writeup about using an auto research agent for Parameter Golf: Autoscaling Autoresearch. The setup was very cool. Tony Chen handed Claude Code a set of Modal skills, basically markdown files that taught the agent how to use Modal primitives like sandboxes, modal run, volumes, and parallel sub agents. Then he pointed it at Parameter Golf and let it run.
The agent ran 113 experiments across 238 GPU hours in about 15 hours. That is a completely different scale from my manual workflow, but it also made the shape of the problem very obvious. Parameter Golf is exactly the kind of loop where an agent can help, not by magically knowing the answer, but by doing the repetitive work: propose a change, run it, parse the score, check artifact size, update the tracker, and decide what to try next.
I did that loop manually and slowly. Next, I want to try setting up an auto research loop of my own and use the learnings from this challenge on another task.
Did I Beat The Leaderboard
No, I did not beat the leaderboard. I improved my personal 1xH100 baseline from 1.36785 to around 1.284, and I had one invalid run at 1.28052, but that is not the same thing as climbing the official leaderboard.
The leaderboard was already far ahead, and the best approaches were combining stronger tokenizers, recurrence, parallel residuals, score first TTT, careful quantization, and much more disciplined iteration than I could do manually in that time. Still, I am happy I did this. I learned more from these failed and half successful runs than I would have learned by only reading the leaderboard.
What I Learned
The biggest lesson is that small model training is not easier just because the model is small. In some ways it is harder. Every byte matters. Every layer matters. Every tokenizer choice matters. The artifact export matters. The compression roundtrip matters. The evaluation mode matters.
I also learned that a good experiment tracker is not optional. Without the table, I would not remember which result was valid, which one used sp4096, which one used sliding eval, and which one only looked good before export. A cool idea is not enough. It has to survive the rules, and the rules here were very good at exposing weak ideas quickly.
Where This Leaves Me
I started late, ran on 1xH100, moved from RunPod to Modal, tried a bunch of ideas, improved my own baseline, broke a few things, and did not beat the leaderboard. That is still a good outcome for me.
This challenge made efficient pretraining feel much more concrete. Not as a paper topic, but as a loop I could run, measure, mess up, and understand a little better each time. And honestly, that is enough reason for me to keep going.
Links
Challenge
My Work
Related Posts
Why I Tried This
In April I decided to participate in OpenAI Model Craft: Parameter Golf. The challenge was to train the best language model that fits inside a
16 MBartifact and finishes training in under10 minuteson8xH100 SXMGPUs. The score is bits per byte on FineWeb validation, so lower is better.What made it interesting to me was that there was no hard parameter count limit. The real limit was whether the final artifact fit, whether training finished in time, and whether the model actually compressed text better. It was not just "make the model bigger." It was more like: can you make something small, compressed, slightly weird, and still useful?
I started late. The challenge ran from March 18 to April 30, 2026, but I only started properly around April 17. So I was not entering with a polished research plan. I was entering with curiosity, a fork of the repo, cloud GPU credits, and a lot of questions.
The First Thing I Had To Understand
The first thing I had to understand was
BPB, or bits per byte. I understood it as a tokenizer agnostic compression score. That mattered because I could try different tokenizers and vocab sizes, but the final evaluation still came back to the same thing: how well the model compressed the validation bytes.The next thing was artifact size. At first
16 MBsounds impossibly tiny, but the baseline exports the model through int8 plus zlib compression, so raw model size has more room than it first looks like. Still, size became the thing I had to keep checking again and again. A run could have a betterval_bpb, but if the compressed artifact crossed16,000,000bytes, it was not useful for the actual challenge.That became the first real lesson for me: in Parameter Golf, a result is not a result until the score and the artifact size both survive.
Starting On RunPod
I first tried the official RunPod path because the challenge was built around RunPod and had a template for it.
The setup was fairly direct. Create a pod, pick the Parameter Golf template, attach storage, SSH in, clone the repo, download the data, and run the training script. I also learned very quickly that storage choices matter here because the pod can be temporary, while the experiments need to survive beyond one session.
My first personal baseline was the unmodified OpenAI provided code on
1xH100, one training shard, and the 10 minute wallclock cap.That run gave me a
val_bpbof1.36785005, aval_lossof2.30955750, and1161steps before the wallclock cap. The raw submission was around67.3 MB, but after int8 plus zlib compression it came down to around13.1 MB, which was safely inside the16 MBlimit. Peak memory was only around10.2 GiB, so at least on the baseline path, memory was not the scary part.That number became my personal benchmark. If a change did not beat
1.36785on roughly the same1xH100setup, I knew it was probably not worth thinking about as a serious direction. The official leaderboard was a very different world though. Around mid April, the top scores were already much lower, and they were using techniques I had not explored yet.So I kept two comparisons separate in my head. My
1xH100baseline was for learning and comparing my own ideas. The leaderboard was the real mountain.Why I Moved To Modal
RunPod worked, but for my way of experimenting it felt risky. I was doing short runs, debugging runs, one minute sanity checks, and then 10 minute comparison runs. With RunPod, I had to stay aware of the pod being alive even when I was just reading logs or editing files. That is not ideal when most of the work is iteration.
Modal fit my workflow better because I already use it for my ML experiments, and it charges for active compute time. I could launch detached jobs, save logs and models into a volume, and avoid the feeling that idle infrastructure was quietly eating money.
The cost view made this very concrete. Most of my Parameter Golf spend sat under ephemeral app runs, and the chart clearly showed the bursty nature of the work. This is exactly why Modal made sense for me here. I was not trying to keep a long running machine alive. I was trying to run a lot of short experiments without turning every pause into a cost problem.
The final setup became my fork of OpenAI's Parameter Golf repo, on the
mri/lab-setupbranch, running throughmodal_train_gpt.pyon1xH100 SXMwith one training shard and a 10 minute wallclock cap. I stored logs in/mnt/experiments/logs/, models in/mnt/experiments/models/, and kept the run history in EXPERIMENTS.md because without a tracker these experiments become impossible to reason about.My Experiment Strategy
The workflow became simple: run tiny jobs to catch bugs, then run 10 minute
1xH100jobs for real comparisons, and only think about8xH100if the idea already looked good and the artifact size was valid. I did not want to spend final submission level money on a broken idea.The early wins came from boring changes. Longer sequence length helped. More layers sometimes helped, but crossed the size limit.
sp4096with sliding evaluation became the first direction that felt actually interesting.val_bpbsp10241.367850.000013.1 MBsp4096sliding eval1.28724-0.080615.37 MBsp4096QK gain5.01.28397-0.083915.51 MBsp8192loop parallel1.28052-0.087321.31 MB← Swipe table to see more
The BPB frontier plot makes the progression easier to see than the table alone. The red lower envelope is basically the path of ideas that actually moved my score down. A lot of runs existed around it, but only a few changed the frontier.
The size plot is the more painful one. It shows why the last row is such a Parameter Golf result. The
sp8192loop parallel run had the lowest BPB I saw, but it landed far beyond the16 MBline. The best valid run was not the best scoring run, and that difference is basically the whole challenge.The Ideas I Tried
The early phase was env only. I changed things through environment variables forwarded into the training script, mostly to understand which knobs mattered before touching code. After that I added the sliding evaluation path, where validation could use overlapping windows instead of only the stock evaluation route. That change helped the
sp4096setup a lot and became one of the clearer improvements in the whole run history.Then I tried a Universal Transformer style idea with fewer physical blocks, more virtual depth, and depth conditioning. I liked the idea because it felt different and parameter efficient, but the aggressive shared block version did not beat the simpler
sp4096direction. A less aggressive half untied version was better, but still not enough to become the main path.After that I tried a random MLP projection adapter idea, and that one failed badly. It got worse and the artifact was invalid. I also tried score first test time training. My understanding from this run was that TTT needs a strong enough base model to be useful. Enabling it too early did not help me. It made the score worse.
The final interesting direction was
sp8192with looped layers and parallel residual style changes. Those runs got closer on score, but the size problem became much harder because the embeddings were large. I also learned that compression and quantization can look promising before export, then collapse after the roundtrip validation. That is a brutal but useful kind of failure because it tells you exactly where the idea broke.This is the part I liked most about the challenge. The failure modes were not vague. A run could have a good score but be too large. It could fit under the size limit but score worse. It could have clever quantization but collapse after export. It could add architecture complexity but then get fewer steps before the wallclock cap. Every idea had a cost.
A Modal Run That Felt Like The Real Setup
Once the Modal flow was working, the runs felt cleaner.
This screenshot is from one of the Universal Transformer follow up runs. It finished successfully, saved the log, saved the int8 model artifact, and committed everything to the Modal volume.
The run itself was not some leaderboard breakthrough, but the infrastructure finally felt like something I could trust. I could launch an experiment, walk away, and come back to logs and artifacts in the same place. That matters a lot when the whole game is iteration.
The Auto Research Agent Thing
One reason this challenge stayed in my head was Modal's own writeup about using an auto research agent for Parameter Golf: Autoscaling Autoresearch. The setup was very cool. Tony Chen handed Claude Code a set of Modal skills, basically markdown files that taught the agent how to use Modal primitives like sandboxes,
modal run, volumes, and parallel sub agents. Then he pointed it at Parameter Golf and let it run.The agent ran
113experiments across238GPU hours in about15hours. That is a completely different scale from my manual workflow, but it also made the shape of the problem very obvious. Parameter Golf is exactly the kind of loop where an agent can help, not by magically knowing the answer, but by doing the repetitive work: propose a change, run it, parse the score, check artifact size, update the tracker, and decide what to try next.I did that loop manually and slowly. Next, I want to try setting up an auto research loop of my own and use the learnings from this challenge on another task.
Did I Beat The Leaderboard
No, I did not beat the leaderboard. I improved my personal
1xH100baseline from1.36785to around1.284, and I had one invalid run at1.28052, but that is not the same thing as climbing the official leaderboard.The leaderboard was already far ahead, and the best approaches were combining stronger tokenizers, recurrence, parallel residuals, score first TTT, careful quantization, and much more disciplined iteration than I could do manually in that time. Still, I am happy I did this. I learned more from these failed and half successful runs than I would have learned by only reading the leaderboard.
What I Learned
The biggest lesson is that small model training is not easier just because the model is small. In some ways it is harder. Every byte matters. Every layer matters. Every tokenizer choice matters. The artifact export matters. The compression roundtrip matters. The evaluation mode matters.
I also learned that a good experiment tracker is not optional. Without the table, I would not remember which result was valid, which one used
sp4096, which one used sliding eval, and which one only looked good before export. A cool idea is not enough. It has to survive the rules, and the rules here were very good at exposing weak ideas quickly.Where This Leaves Me
I started late, ran on
1xH100, moved from RunPod to Modal, tried a bunch of ideas, improved my own baseline, broke a few things, and did not beat the leaderboard. That is still a good outcome for me.This challenge made efficient pretraining feel much more concrete. Not as a paper topic, but as a loop I could run, measure, mess up, and understand a little better each time. And honestly, that is enough reason for me to keep going.
Links
Challenge
My Work
Related Posts