Why I Wanted To Do This
I'd already messed around with cold start SFT, stumbled through a few RL experiments, and squeezed models down for Parameter Golf. But pre-training still felt like a black box. I wanted to start from actual random weights, feed the model raw internet text, and watch it learn next-token prediction from nothing.
So the goal was simple: train a real base model. Small enough that I could wrap my head around it and actually pay for the compute, but not so small that the whole thing would feel like a toy. GPT-2 small from 2019 was about 124M parameters, and that number just stuck in my head as a useful anchor.
What I actually trained was a 123.6M parameter decoder-only causal LM on a 2B token slice of FineWeb-Edu. I kept the GPT-2 tokenizer for simplicity, but the architecture itself is modern: RoPE, RMSNorm, SwiGLU, no linear biases, and tied input-output embeddings.
The Setup
I kept the training config deliberately simple. 12 layers, 12 heads, hidden size 768, context length 1024, GPT-2 vocab of 50257. Batch size 8, 244000 steps, max LR 3e-4, min LR 3e-5, 2000 warmup steps, 0.1 weight decay, gradient clipping at 1.0.
modal:
gpu: H100
tracking:
backend: trackio
project: first-llm-pre-train
run_name: 124m-fineweb-edu-2b-h100
space_id: mrinaalarora/trackio
model:
vocab_size: 50257
block_size: 1024
n_layer: 12
n_head: 12
n_embd: 768
dropout: 0.0
train:
dataset_dir: /vol/datasets/fineweb_edu_gpt2_2b_train
val_dataset_dir: /vol/datasets/fineweb_edu_gpt2_20m_val
checkpoint_dir: /vol/checkpoints/124m_main_2b
batch_size: 8
max_steps: 244000
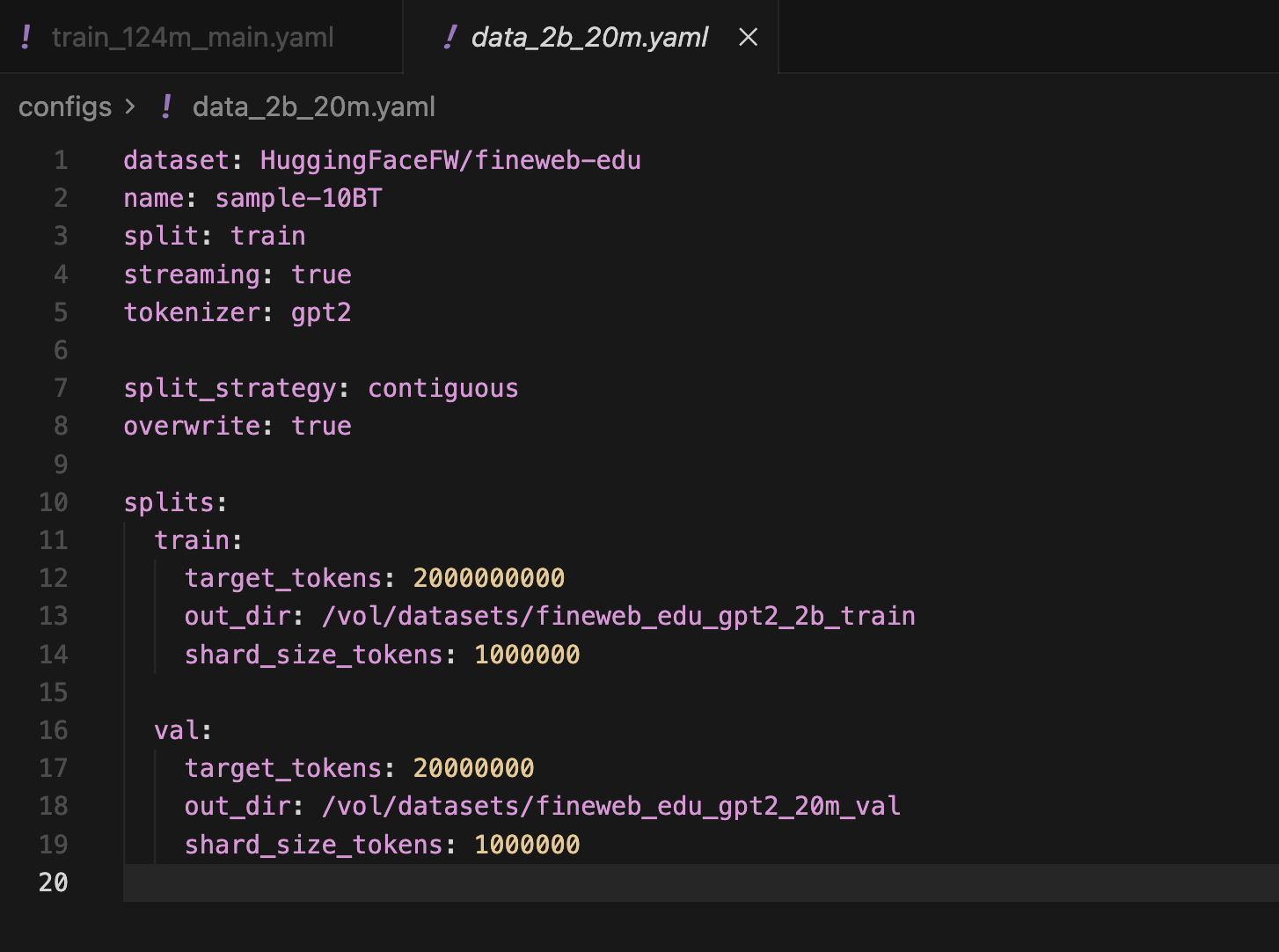
For data I grabbed a contiguous 2B token training split from FineWeb-Edu plus a 20M token validation split, both pretokenized with the GPT-2 tokenizer.
I ran the actual training job on Modal with a single NVIDIA H100. I also hooked up Trackio to stream metrics live into a Hugging Face Space, which meant I could watch the run from a dashboard instead of just tailing logs in a terminal.
The live dashboard for the run is here: first-llm-pre-train Trackio dashboard.
The Actual Training Run
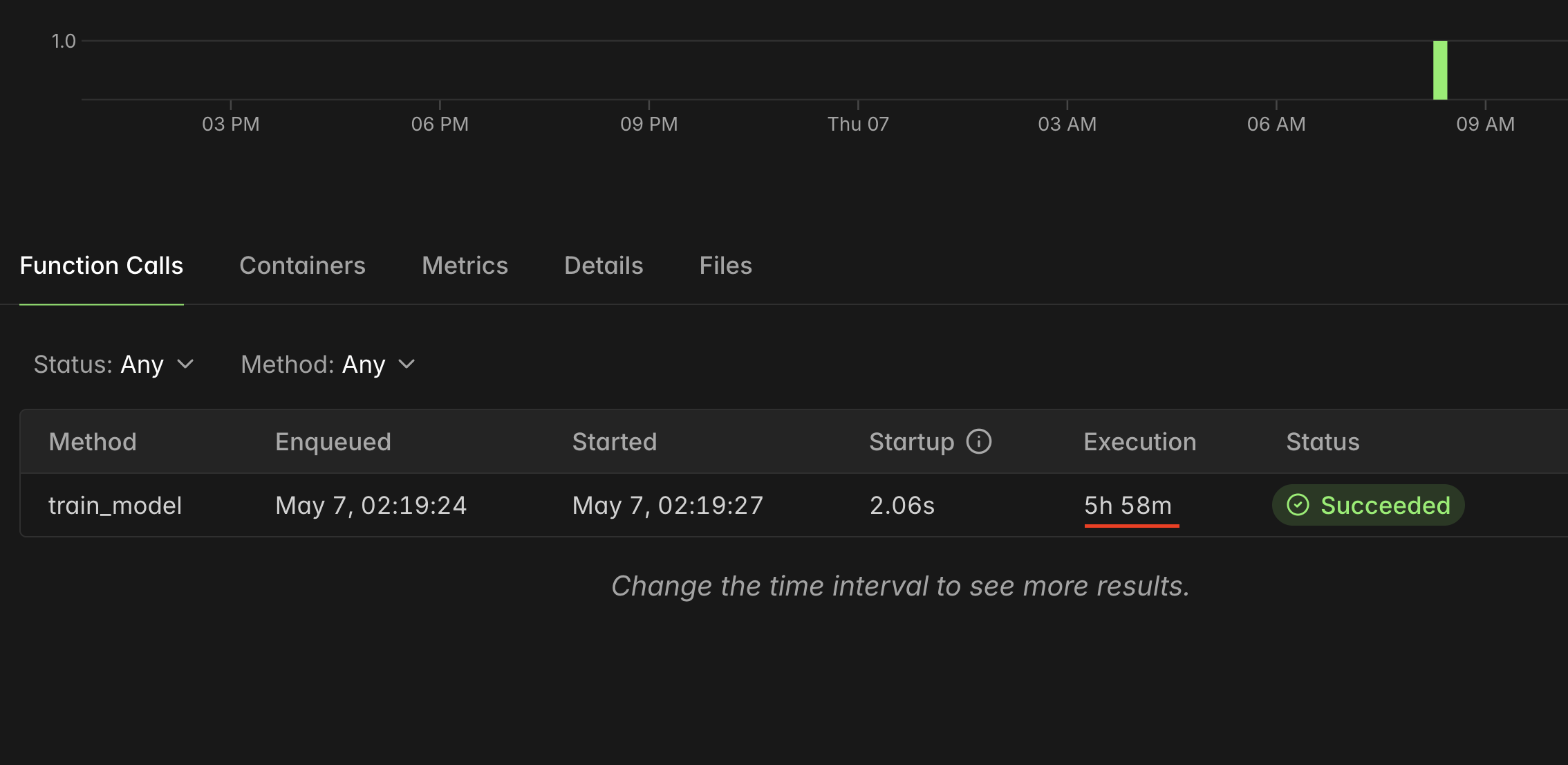
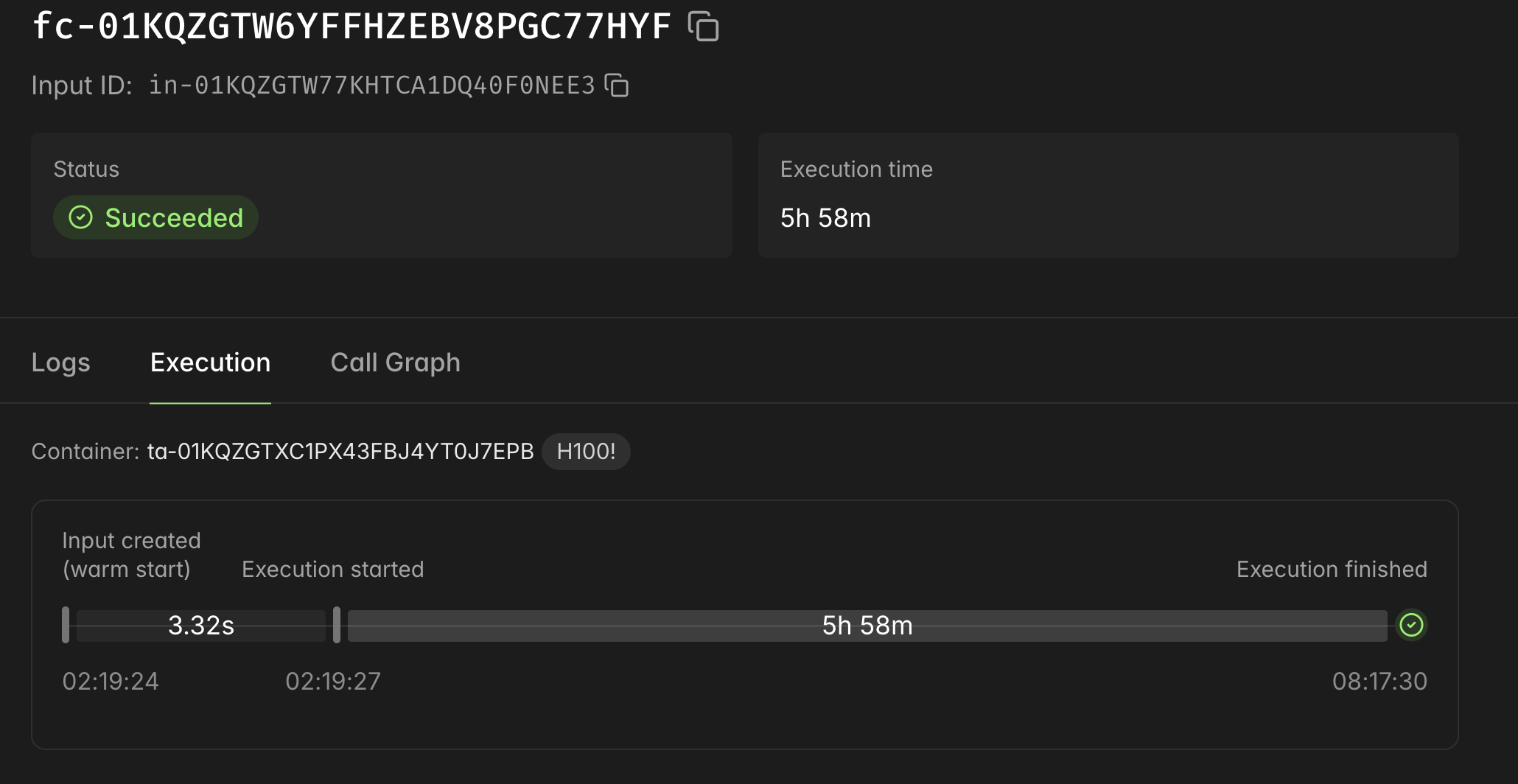
The final run took about 6 hours on the H100. Modal showed the function call finishing successfully after 5h 58m. After a bunch of smaller test runs and config tweaks that kept breaking or timing out, seeing that clean green success badge felt good.
The checkpoint folder on the Modal volume had what I actually needed: best.pt, last.pt, metrics.jsonl, and run_summary.json.
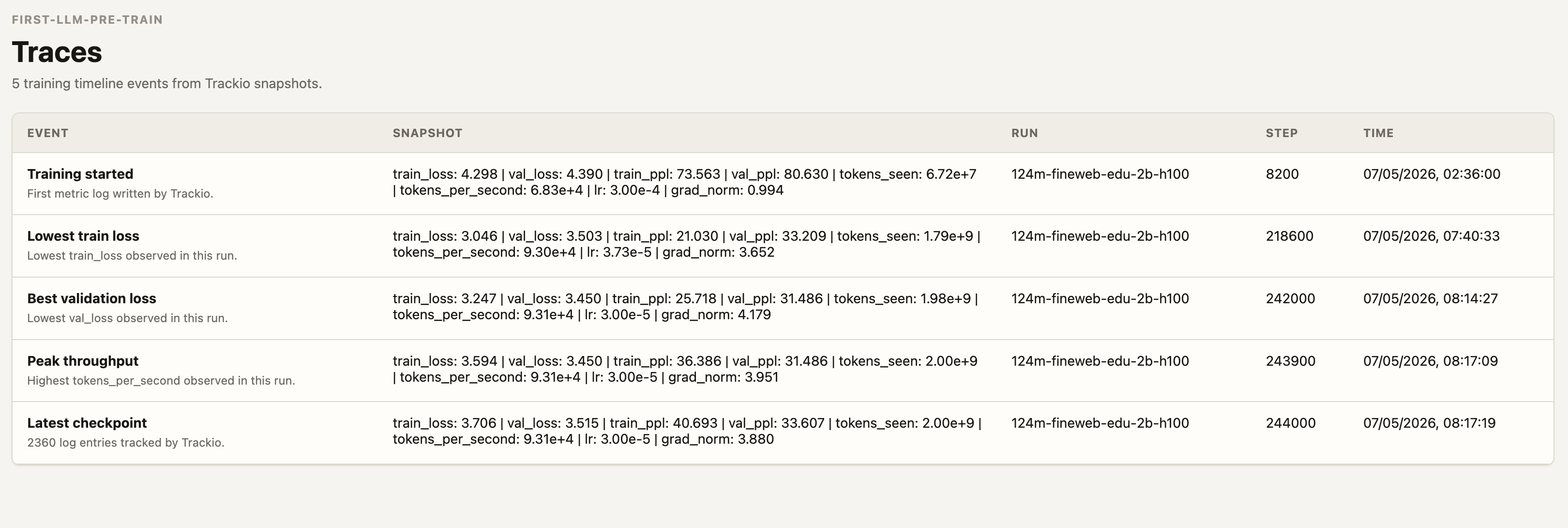
Raw train loss started around 10.98 and ended at 3.70. Best validation loss was 3.45 at step 242K. Final validation loss sat around 3.51. The run chewed through about 1.99B tokens, finished at 244K steps, and throughput near the end was roughly 93K tokens per second.
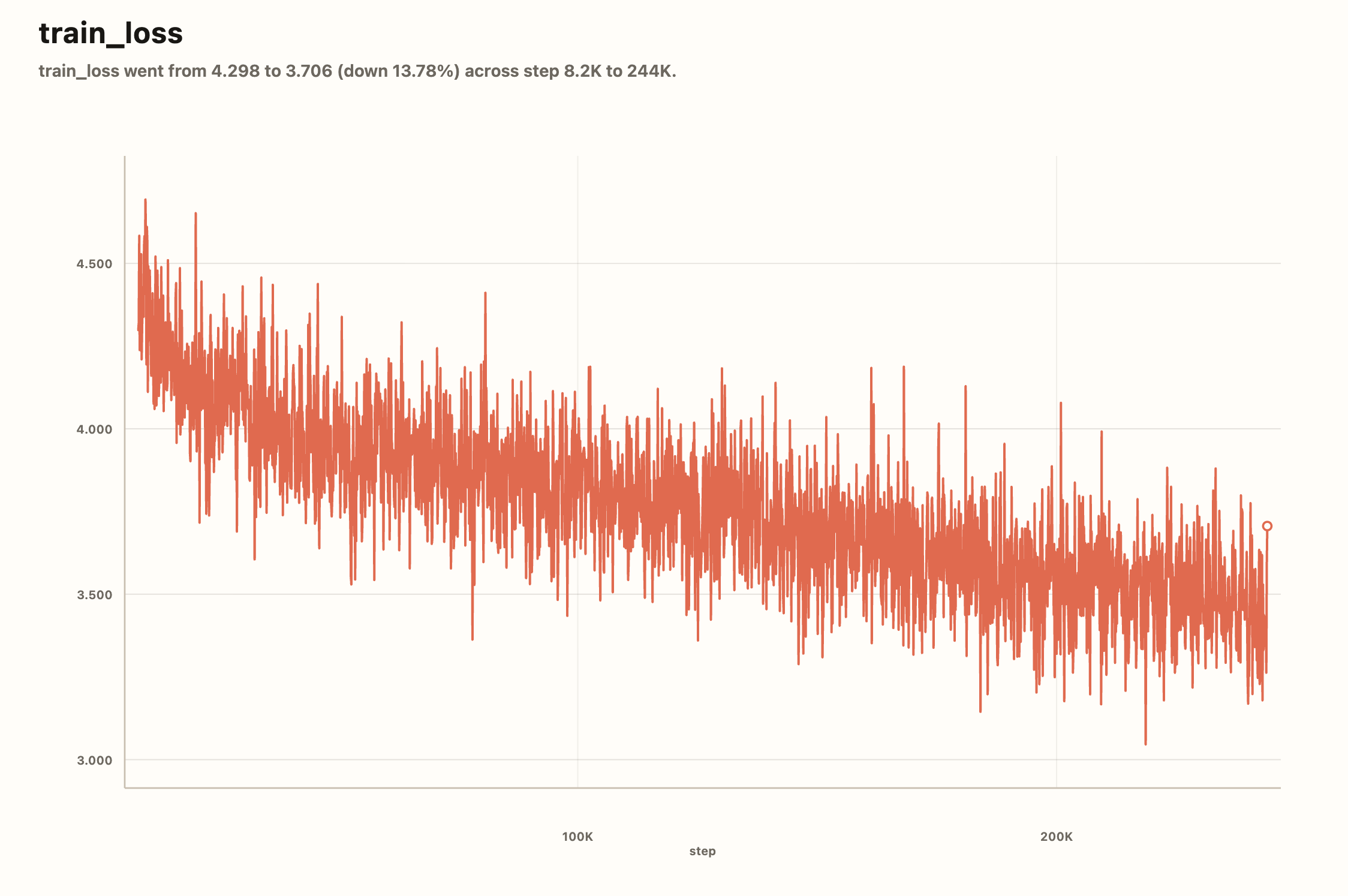
The Loss Curves
For the first time I watched loss curves do what all the write-ups claim they do. The train loss was messy, yet the trend was unmistakable.
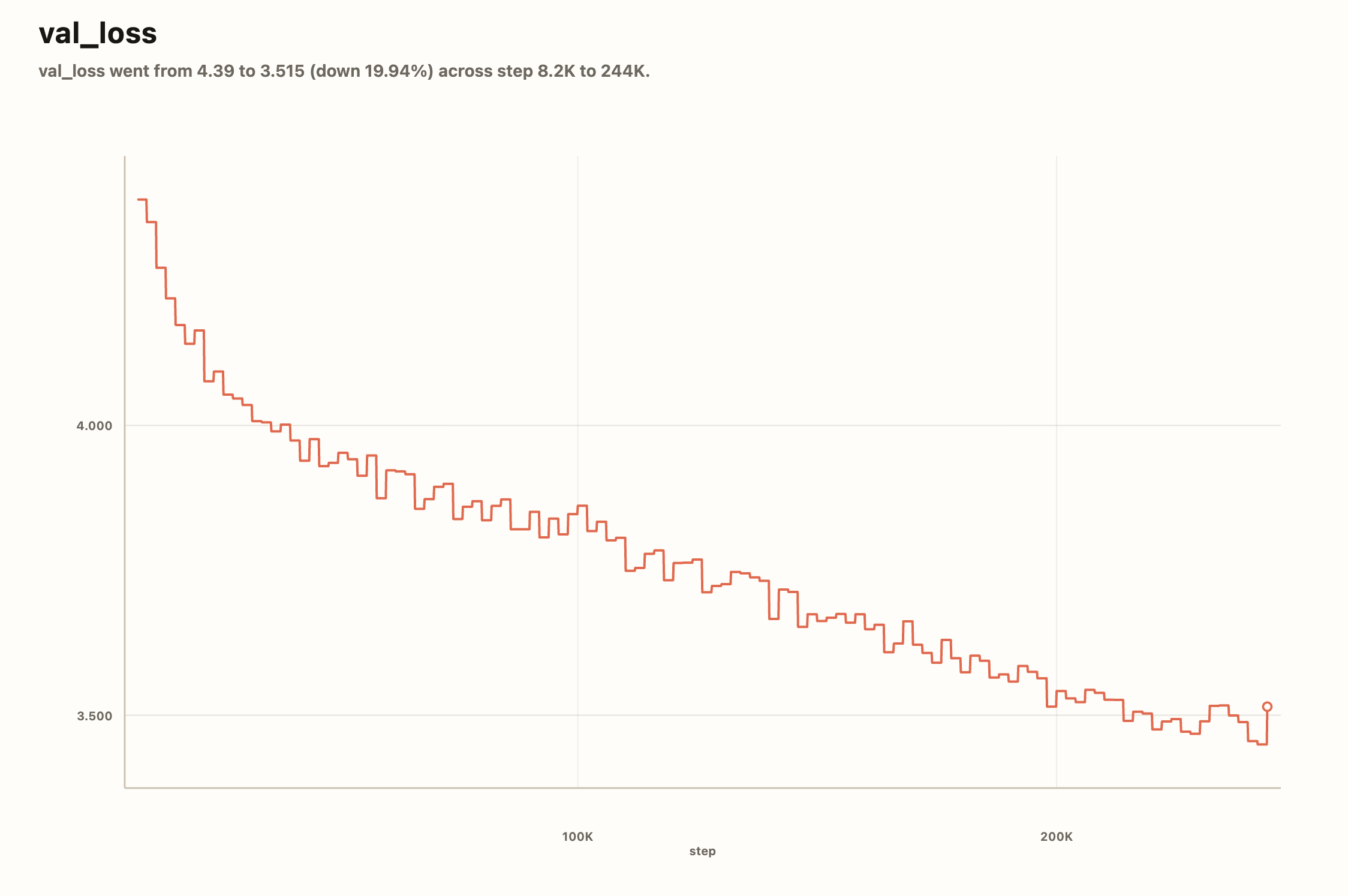
The validation loss was cleaner and around step 242K it hit its lowest point, and that was the checkpoint I pushed to Hugging Face.
Publishing The Base Model
Once the run finished, I converted the best checkpoint and pushed the weights to Hugging Face: mrinaalarora/mrinaal-124m-base.
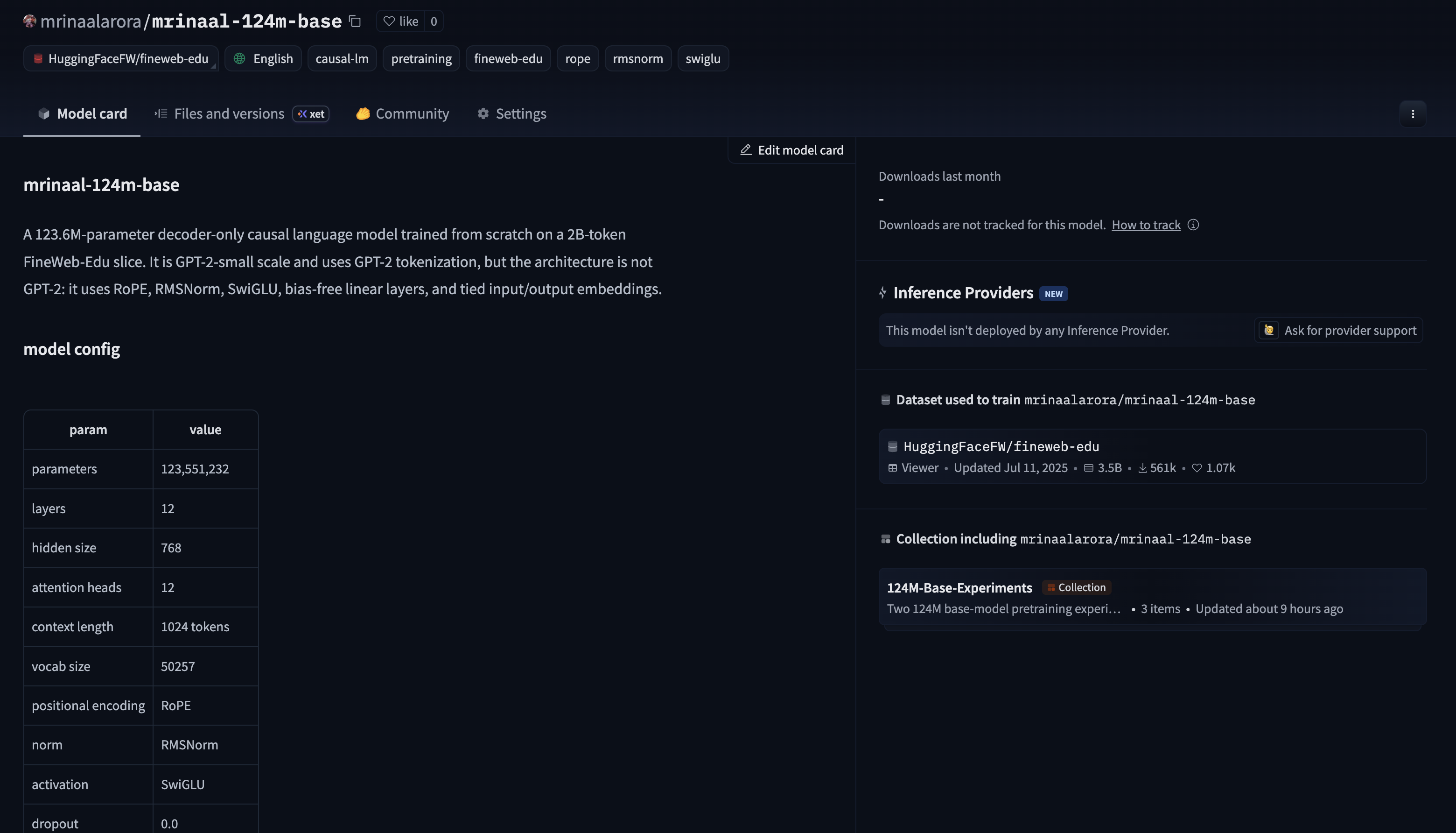
The model card is deliberately plain. I wrote what the model is and what it is not. GPT-2 scale, but not GPT-2. Trained from scratch on a 2B token slice of FineWeb-Edu. Uses the GPT-2 tokenizer, but the internals are RoPE, RMSNorm, SwiGLU, no linear biases, and tied embeddings.
Forward pass is: embeddings → transformer blocks → final norm → language modeling head.
class DecoderOnlyTransformer(nn.Module):
def __init__(self, config: ModelConfig):
super().__init__()
self.config = config
self.token_embedding = nn.Embedding(config.vocab_size, config.n_embd)
self.blocks = nn.ModuleList([TransformerBlock(config) for _ in range(config.n_layer)])
self.final_norm = RMSNorm(config.n_embd, config.norm_eps)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.token_embedding.weight = self.lm_head.weight
self.apply(self._init_weights)
def forward(
self,
input_ids: torch.Tensor,
targets: torch.Tensor | None = None,
) -> tuple[torch.Tensor, torch.Tensor | None]:
x = self.token_embedding(input_ids)
for block in self.blocks:
x = block(x)
logits = self.lm_head(self.final_norm(x))
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.reshape(-1))
return logits, loss
The first inference samples were not impressive , but that was never the goal. The goal was that random weights had turned into something that could produce coherent autocomplete-style text. The outputs were rough, repetitive, and unmistakably base-model-like.
The Continued Pre-Training Follow Up
Once the 2B token base model was finished, I ran a small continued pre-training pass on top of it.
The v2 checkpoint is at mrinaalarora/mrinaal-124m-base-v2. It adds another 1B next-token-prediction tokens on a mixed blend: 50% FineWeb-Edu dedup, 30% DCLM baseline, 15% FineMath, and 5% Cosmopedia v2.
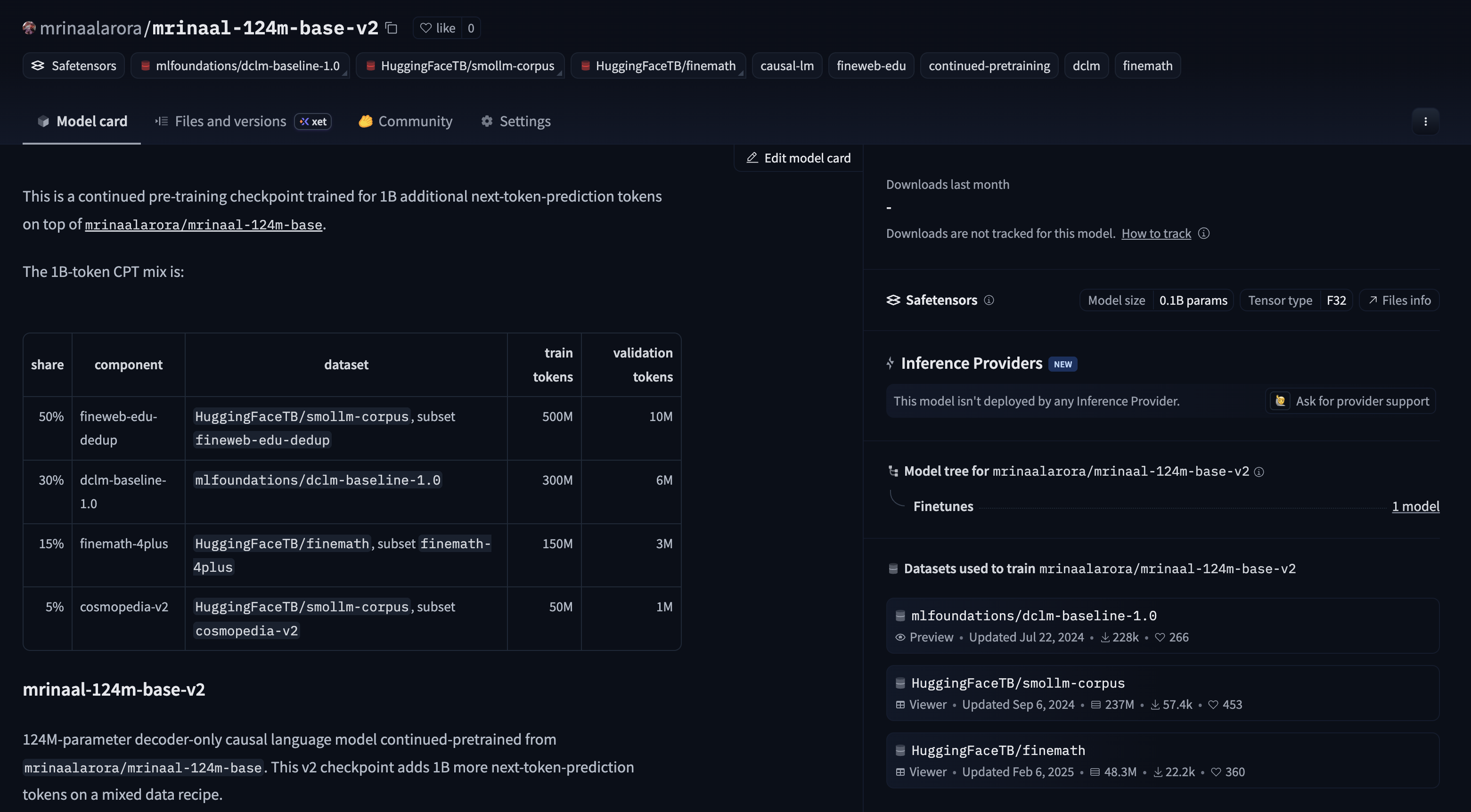
The v2 run was an experiment: what happens if I keep training the same model with a broader but slightly more targeted mix?
A Small HellaSwag Check
I also ran a HellaSwag eval comparing the 2B token base model against the continued pre-training checkpoint. The result was not a tidy win. Both models scored 28.44% overall, only a few points above the 25% random baseline, but the extra 1B tokens did not lift the headline number.
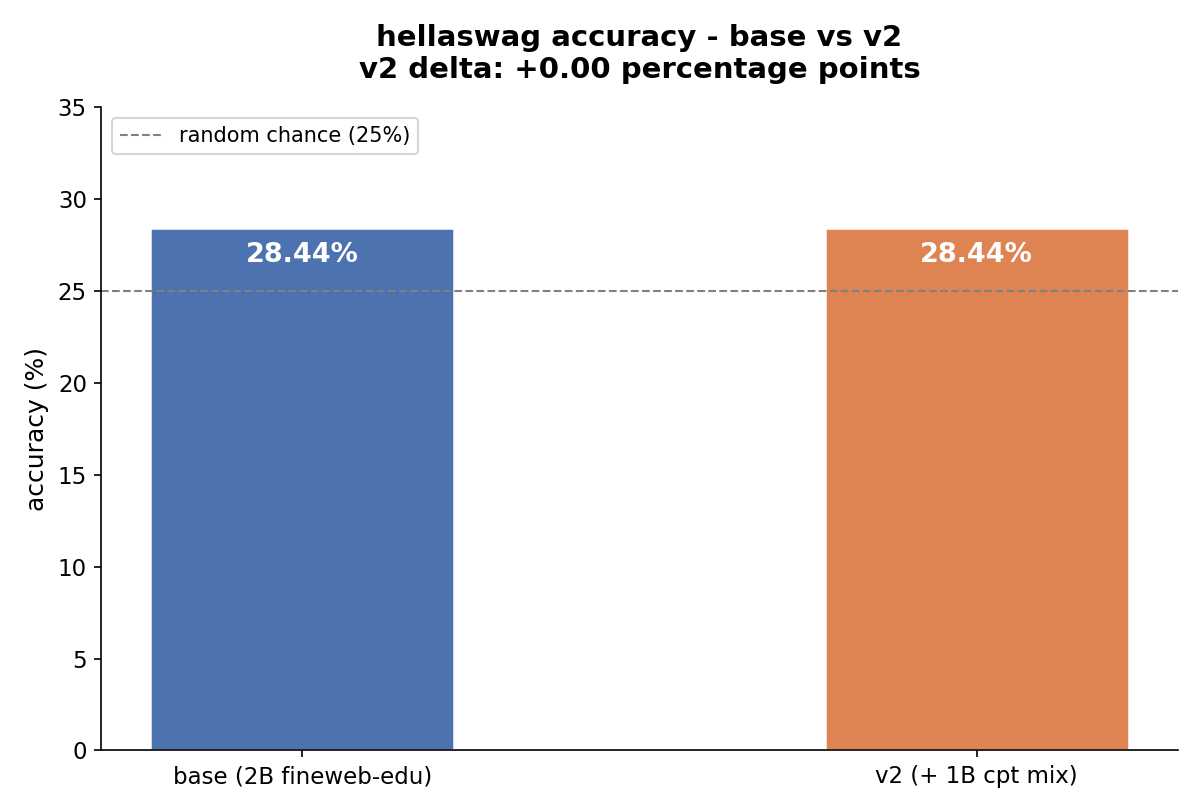
Continued pre-training definitely changed the model, but this single eval did not demonstrate broad improvement.
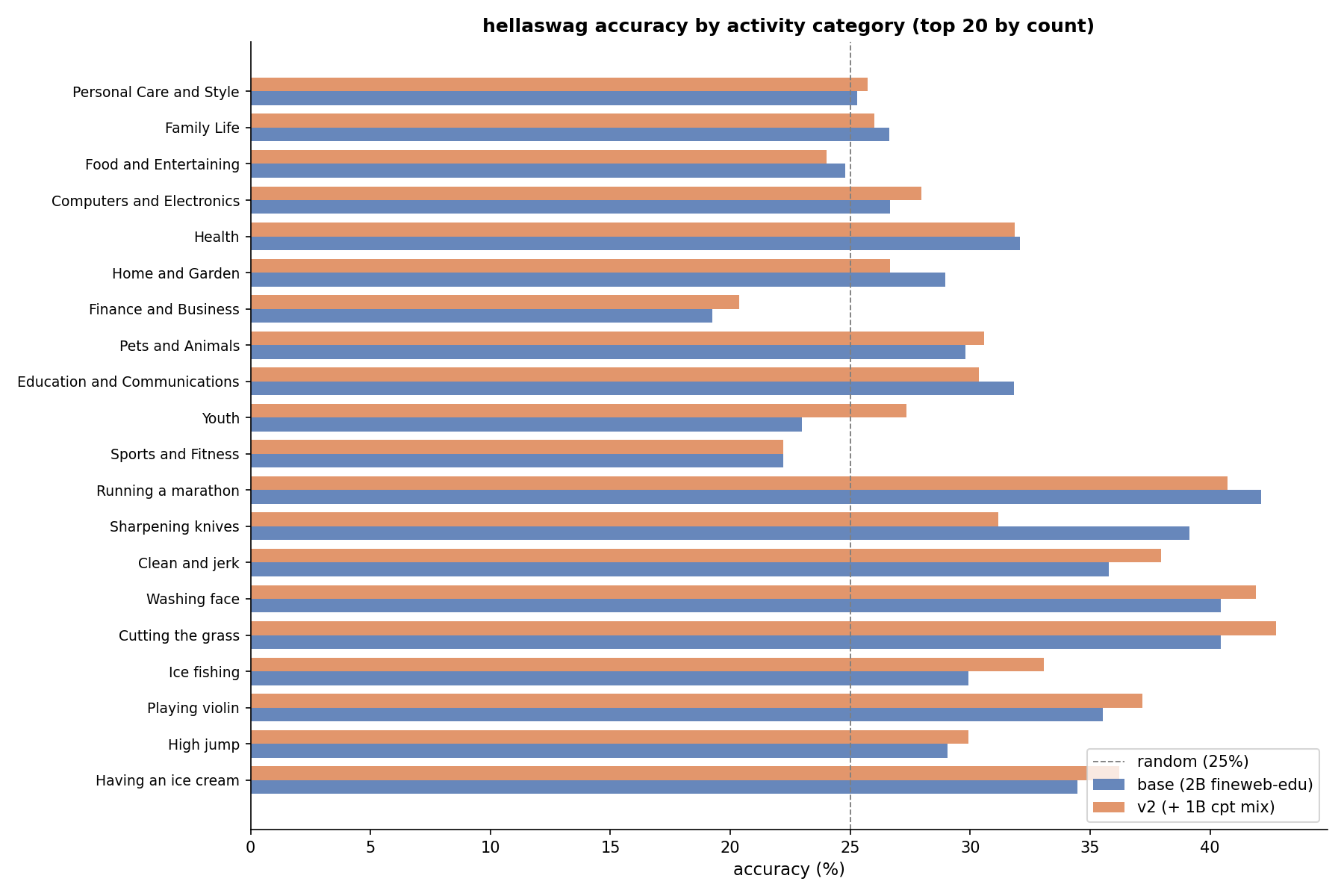
Still, I view it as progress. I now have a base checkpoint, a continued pre-training checkpoint, and a minimal comparison pipeline. Far from a rigorous eval setup, but it is a loop I can iterate on.
What I Learned
The biggest takeaway for me is that pre-training is simpler in concept than it looks from the outside. The objective really is just next-token prediction. But every surrounding detail is serious business. Data prep, tokenization, checkpointing, validation splits, metric logging, picking the right checkpoint to upload. None of it is optional.
I also finally understood why researchers obsess over training curves. When the loss drops in a sensible pattern, you can start believing the system is actually learning.
Scale was the other surprise. 124M parameters and 2B tokens is a rounding error next to frontier runs, yet it was large enough that I could feel the real shape of the problem.
Where This Leaves Me
I am still early in my independent ML study, but this run gave me a lot of confidence. The same loop I just walked through is probably not that different from what frontier labs do when they pre-train their multi-trillion parameter models. Same next-token prediction objective, same checkpointing and validation rituals, same obsession over loss curves. The difference is scale, proprietary data mixes, and architecture tricks they rarely open source. Now I have walked through a small version of the whole thing myself.
Links
Models
Data And Tracking
Why I Wanted To Do This
I'd already messed around with cold start SFT, stumbled through a few RL experiments, and squeezed models down for Parameter Golf. But pre-training still felt like a black box. I wanted to start from actual random weights, feed the model raw internet text, and watch it learn next-token prediction from nothing.
So the goal was simple: train a real base model. Small enough that I could wrap my head around it and actually pay for the compute, but not so small that the whole thing would feel like a toy. GPT-2 small from 2019 was about
124Mparameters, and that number just stuck in my head as a useful anchor.What I actually trained was a
123.6Mparameter decoder-only causal LM on a2Btoken slice of FineWeb-Edu. I kept the GPT-2 tokenizer for simplicity, but the architecture itself is modern: RoPE, RMSNorm, SwiGLU, no linear biases, and tied input-output embeddings.The Setup
I kept the training config deliberately simple.
12layers,12heads, hidden size768, context length1024, GPT-2 vocab of50257. Batch size8,244000steps, max LR3e-4, min LR3e-5,2000warmup steps,0.1weight decay, gradient clipping at1.0.For data I grabbed a contiguous
2Btoken training split from FineWeb-Edu plus a20Mtoken validation split, both pretokenized with the GPT-2 tokenizer.I ran the actual training job on Modal with a single NVIDIA H100. I also hooked up Trackio to stream metrics live into a Hugging Face Space, which meant I could watch the run from a dashboard instead of just tailing logs in a terminal.
The live dashboard for the run is here: first-llm-pre-train Trackio dashboard.
The Actual Training Run
The final run took about
6hours on the H100. Modal showed the function call finishing successfully after5h 58m. After a bunch of smaller test runs and config tweaks that kept breaking or timing out, seeing that clean green success badge felt good.The checkpoint folder on the Modal volume had what I actually needed:
best.pt,last.pt,metrics.jsonl, andrun_summary.json.Raw train loss started around
10.98and ended at3.70. Best validation loss was3.45at step242K. Final validation loss sat around3.51. The run chewed through about1.99Btokens, finished at244Ksteps, and throughput near the end was roughly93Ktokens per second.The Loss Curves
For the first time I watched loss curves do what all the write-ups claim they do. The train loss was messy, yet the trend was unmistakable.
The validation loss was cleaner and around step
242Kit hit its lowest point, and that was the checkpoint I pushed to Hugging Face.Publishing The Base Model
Once the run finished, I converted the best checkpoint and pushed the weights to Hugging Face: mrinaalarora/mrinaal-124m-base.
The model card is deliberately plain. I wrote what the model is and what it is not. GPT-2 scale, but not GPT-2. Trained from scratch on a
2Btoken slice of FineWeb-Edu. Uses the GPT-2 tokenizer, but the internals are RoPE, RMSNorm, SwiGLU, no linear biases, and tied embeddings.Forward pass is: embeddings → transformer blocks → final norm → language modeling head.
The first inference samples were not impressive , but that was never the goal. The goal was that random weights had turned into something that could produce coherent autocomplete-style text. The outputs were rough, repetitive, and unmistakably base-model-like.
The Continued Pre-Training Follow Up
Once the 2B token base model was finished, I ran a small continued pre-training pass on top of it.
The v2 checkpoint is at mrinaalarora/mrinaal-124m-base-v2. It adds another
1Bnext-token-prediction tokens on a mixed blend:50%FineWeb-Edu dedup,30%DCLM baseline,15%FineMath, and5%Cosmopedia v2.The v2 run was an experiment: what happens if I keep training the same model with a broader but slightly more targeted mix?
A Small HellaSwag Check
I also ran a HellaSwag eval comparing the
2Btoken base model against the continued pre-training checkpoint. The result was not a tidy win. Both models scored28.44%overall, only a few points above the25%random baseline, but the extra1Btokens did not lift the headline number.Continued pre-training definitely changed the model, but this single eval did not demonstrate broad improvement.
Still, I view it as progress. I now have a base checkpoint, a continued pre-training checkpoint, and a minimal comparison pipeline. Far from a rigorous eval setup, but it is a loop I can iterate on.
What I Learned
The biggest takeaway for me is that pre-training is simpler in concept than it looks from the outside. The objective really is just next-token prediction. But every surrounding detail is serious business. Data prep, tokenization, checkpointing, validation splits, metric logging, picking the right checkpoint to upload. None of it is optional.
I also finally understood why researchers obsess over training curves. When the loss drops in a sensible pattern, you can start believing the system is actually learning.
Scale was the other surprise.
124Mparameters and2Btokens is a rounding error next to frontier runs, yet it was large enough that I could feel the real shape of the problem.Where This Leaves Me
I am still early in my independent ML study, but this run gave me a lot of confidence. The same loop I just walked through is probably not that different from what frontier labs do when they pre-train their multi-trillion parameter models. Same next-token prediction objective, same checkpointing and validation rituals, same obsession over loss curves. The difference is scale, proprietary data mixes, and architecture tricks they rarely open source. Now I have walked through a small version of the whole thing myself.
Links
Models
Data And Tracking
Tools